Site-Wide Protection
Ensuring 24/7 Uptime
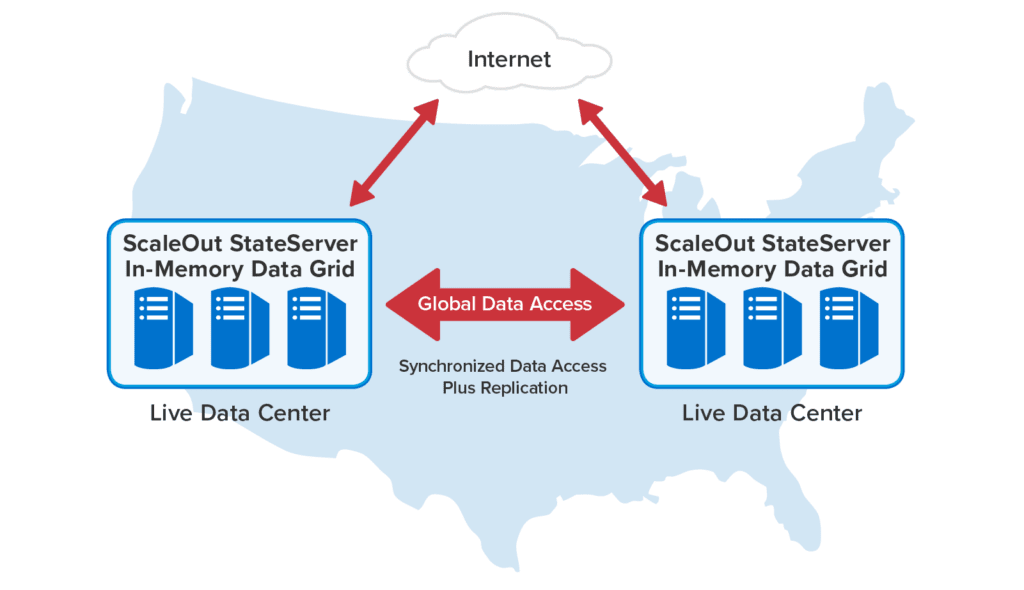
ScaleOut StateServer®, ScaleOut’s in-memory data grid (IMDG), gives you fast data access, scalability, and high availability with distributed, memory-based data storage. But what if the entire data center or cloud region goes offline due to a power failure or catastrophic event? A solid disaster recovery strategy requires handing off the workload to another, healthy data center to avoid service interruptions if the worst occurs.
ScaleOut GeoServer DR (a subset of ScaleOut GeoServer Pro) seamlessly integrates into this recovery strategy by automatically synchronizing the contents of ScaleOut’s in-memory data grids (IMDGs) at up to eight sites. This product continuously replicates updates to memory-based data from a local IMDG to one or more remote IMDGs, keeping fast-changing workloads protected against site-wide failures.
For example, leading e-commerce companies store shopping carts in ScaleOut’s IMDG and use ScaleOut GeoServer DR to replicate them between multiple data centers. If disaster strikes, they shift online customers to an alternative data center using their global load balancer to let them continue shopping without interruption.
Fast, Asynchronous Replication
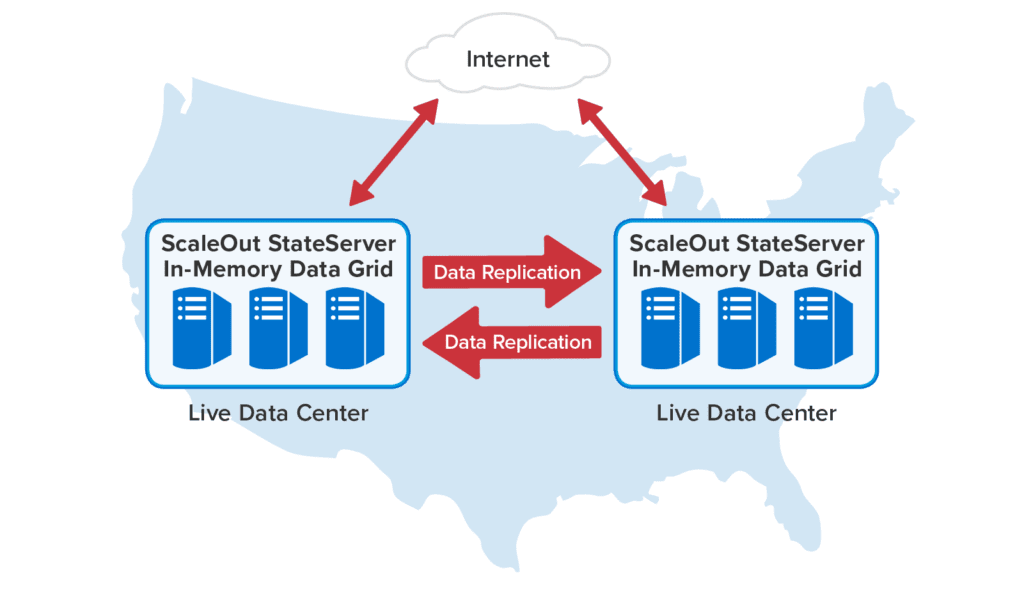
ScaleOut GeoServer DR was designed to replicate updates to live data as fast as possible and with minimal impact on access performance. It uses asynchronous, pipelined, “push” replication, which quickly delivers updates to remote sites while avoiding delays to local accesses. To handle growing workloads, it uses a symmetric, peer-to-peer software architecture that automatically adds connections and scales replication bandwidth as servers are added to the IMDGs.
Optional SSL Support
Replicated data is fully protected from intrusion using either a virtual private network or optional, secure socket connections (SSL).
Support for “Live-Live” Configurations
ScaleOut GeoServer DR fully supports bi-directional replication, allowing all data centers to fully participate in handling the workload.