ScaleOut GeoServer® Pro combines data replication between sites for disaster recovery with synchronized access that simplifies applications and unlocks new use cases.
Web applications, such as ecommerce sites and financial services, often need to replicate fast-changing, in-memory data across multiple data centers or cloud regions. As part of an overall strategy for disaster recovery, cross-site data replication ensures that mission-critical data is continuously available, even if one site goes offline.
Many applications need to use two (and sometimes more) sites in an “active-active” manner, distributing the workload across the sites. Here are some real-world applications we have seen. Ecommerce applications need to maintain shopping carts at multiple sites and distribute the workload from their shoppers with a global load-balancer. Cell phone providers need to keep their lists of available mobile numbers consistent across sites as individual stores allocate them. Conference-management companies need to keep attendee lists and schedules consistent at conference sites and their central data center.
Let’s take a closer look at an ecommerce site using a global load-balancer to distribute incoming web requests to multiple sites. This approach lets the web application take advantage of the processing power at multiple sites during normal operations. However, it creates the challenge of coordinating access to in-memory objects which are replicated across two or more sites. This can add substantial complexity if handled by the application.
Here’s an example of an ecommerce site using a global load-balancer to distribute incoming web requests across two sites, each of which hosts shopping carts within an in-memory data grid (also called a distributed cache), such as ScaleOut StateServer®. A web shopper might select a pair of shoes and place them in the shopping cart followed by selecting a tennis racket. As shown in the following diagram, the global load-balancer sends the first request to site 1 and the second request to site 2 in this example:
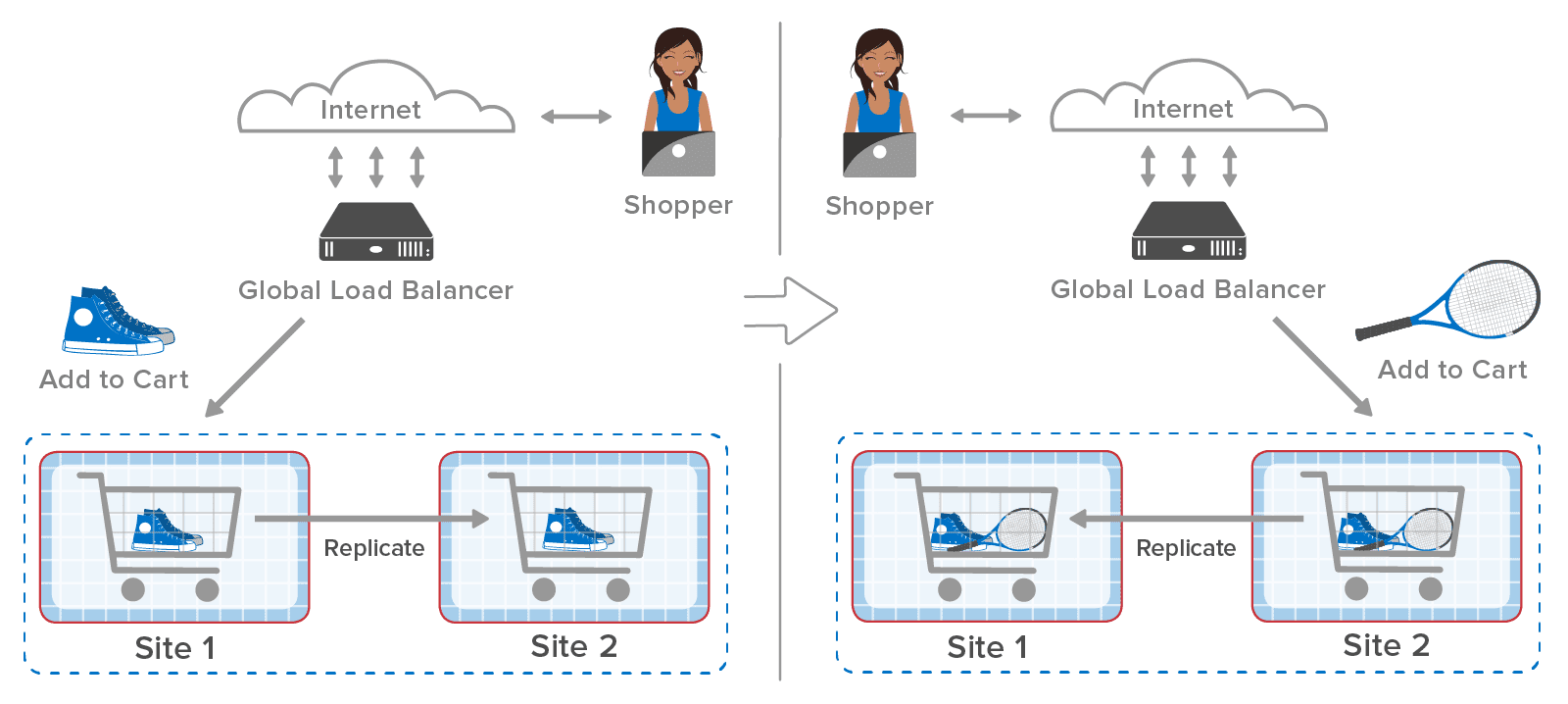
After the first request completes, the in-memory data grid at site 1 replicates the cart to site 2. The global load-balancer then sends the second request to site 2, which adds the tennis racket to the cart. Finally, site 2 replicates the changes back to site 1 so that both sites have the latest copy of the shopping cart.
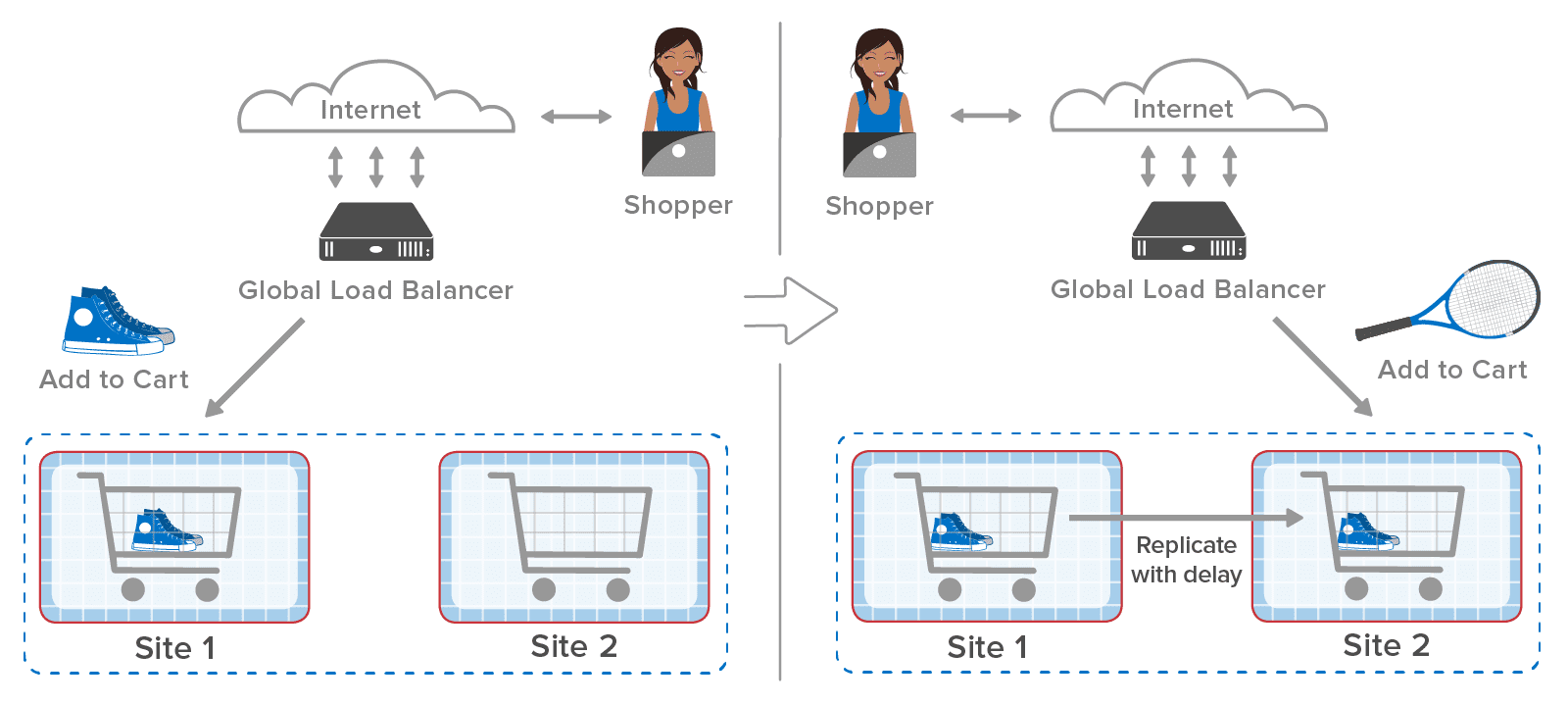
What happens if replication from site 1 to site 2 is slightly delayed? After site 2 puts the tennis racket in the cart, the incoming replicated update arrives and overwrites the cart. This causes both sites to lose the update at site 2, and the shopper will undoubtedly be annoyed to find that the tennis racket is missing from the cart:
The solution to this problem is to have the web applications at both sites synchronize updates to the shopping carts. This ensures that only one site at a time updates the shopping cart and that each site always sees the latest version of the in-memory object. Using ScaleOut GeoServer Pro, applications can use standard object-locking APIs for this purpose, just as they would to coordinate object access within a single in-memory data grid:
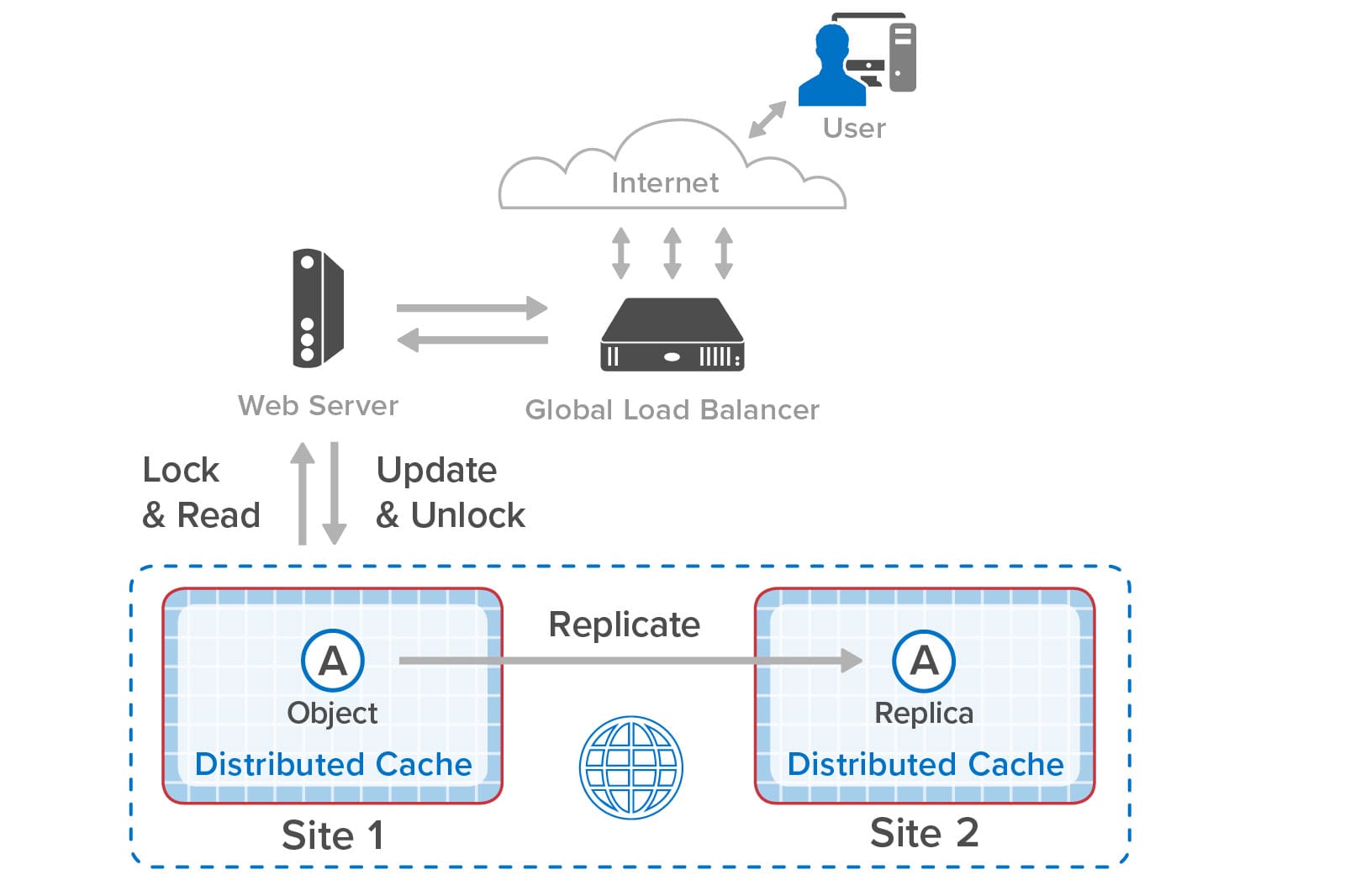
After the web application on site 1 updates and unlocks object A (the shopping cart in our example), site 1 replicates the update to site 2. When the global load-balancer sends the next request to site 2, the web application on that site 2 also locks and reads the object, updates it, and then unlocks it:
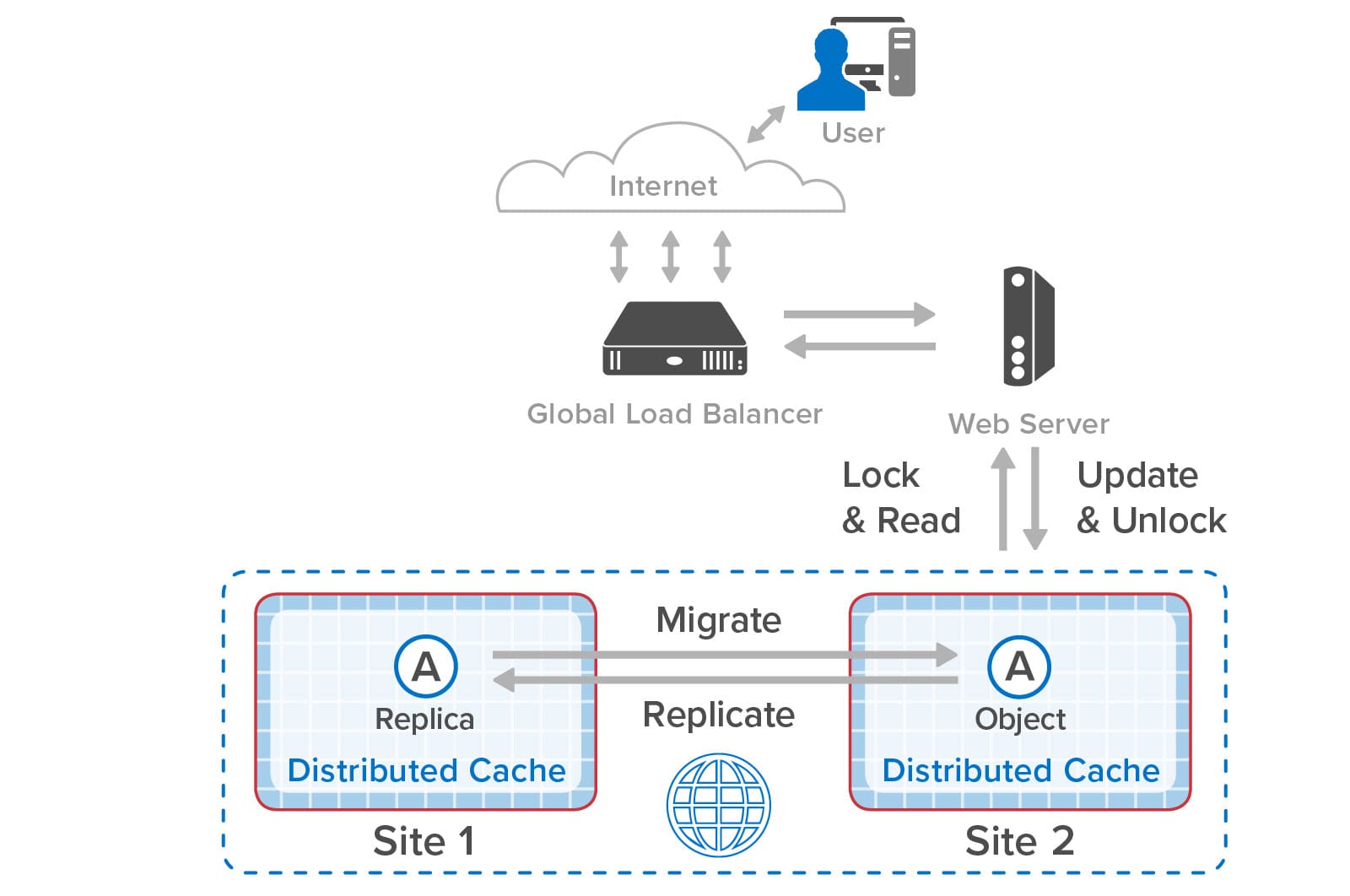
When the object is locked on site 2, ScaleOut GeoServer Pro makes sure that the application sees the latest version of the object. It does so by migrating ownership of the object to site 2 and checking that it has the latest version. Although this requires a round trip to site 1, once a site gains ownership, all further accesses are local until the other site again attempts to lock the object and request ownership. If the global load-balancer avoids ping-ponging between sites with every web request, the latency to lock an object remains low.
Should the wide area network (WAN) connecting the two sites fail, or if the remote site goes offline, the two sites can operate independently; this is called “split brain” mode in distributed systems. They detect the WAN failure and automatically promote local replica objects as needed to gain ownership when requesting a lock. This enables uninterrupted operations that make use of object replicas held at each site. By combining object replication with synchronized access, applications enjoy the full benefits of synchronized object access across sites during normal operations and uninterrupted access during WAN or site outages:
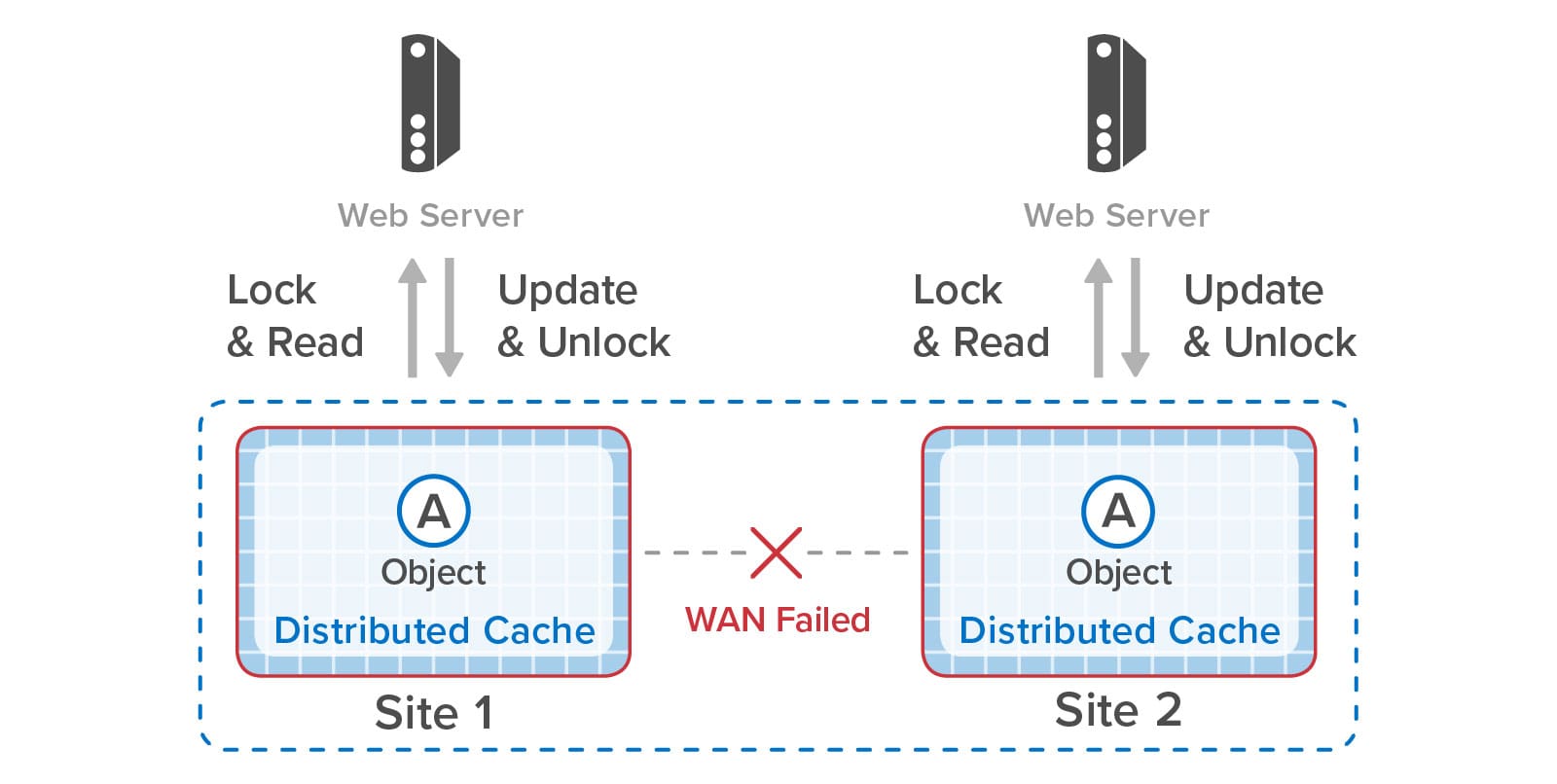
A key challenge created by split-brain mode is how to restore normal operations after an outage has been corrected. For example, the following diagram shows the two sites in our shopping example operating independently during a WAN outage that occurs between the two web requests. Site 1 adds the shoes to its shopping cart but is unable to replicate that update to site 2. The web application on site 2 then places the tennis racket in its shopping cart:
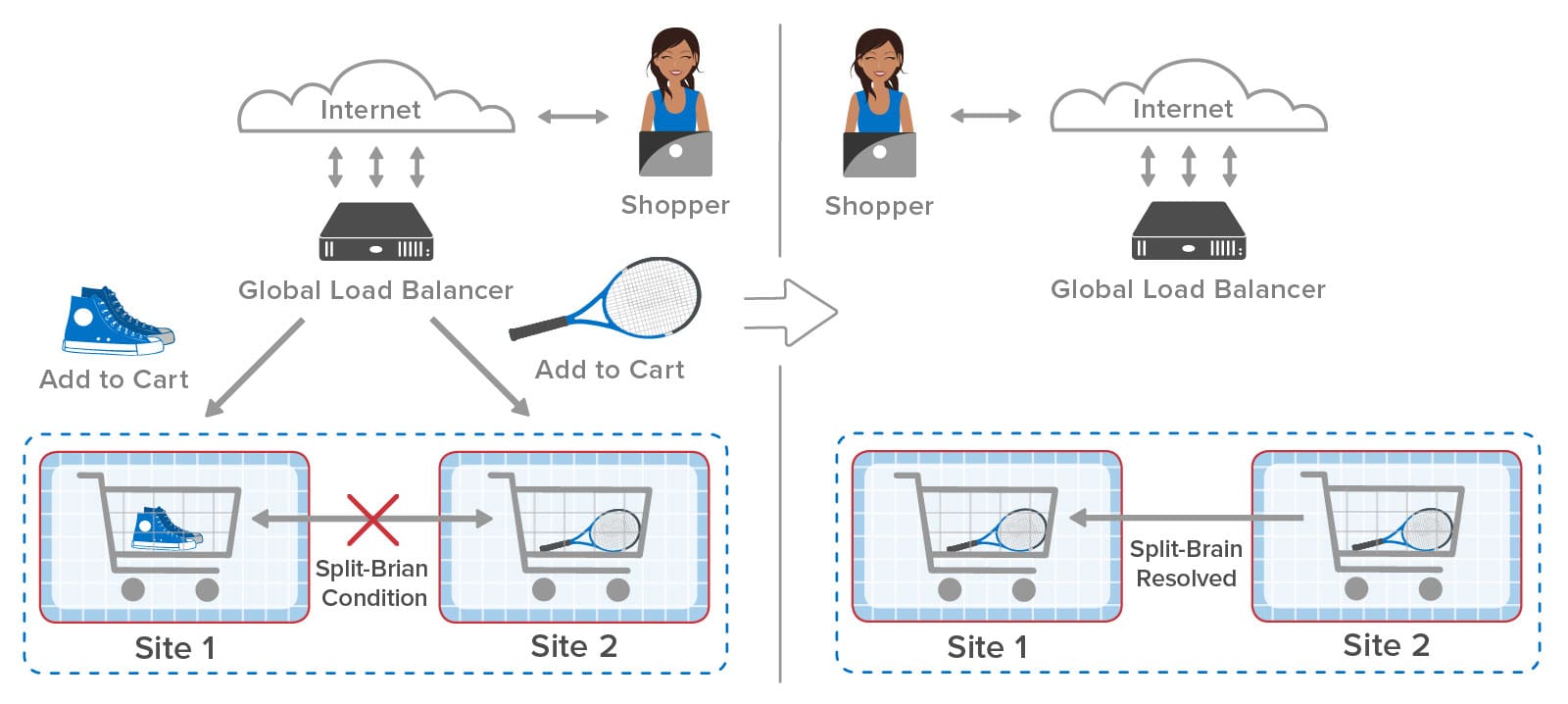
After the WAN is restored, the two sites have to resolve the differences in the contents of their copies of stored objects. Unless the application uses special, conflict-free data types that can be merged (and this is rare for most applications), a heuristic needs to be used to resolve conflicts. ScaleOut GeoServer Pro automatically resolves conflicts for each pair of object copies by selecting the copy with the latest update time or randomly picking one of the copies if the update times are the same. So in this case, both sites are updated with the version of the shopping cart holding the tennis racket. (This will be another source of annoyance for our shopper, but at least the ecommerce site survived a WAN outage without interruption.)
ScaleOut GeoServer Pro resolves split-brain conflicts as it detects them when updates are performed and then are successfully replicated across the WAN. It also has to resolve the fact that both sites now think they own the same object, and it handles this by randomly picking a site to retain ownership. As the two sites attempt to lock and read the object, ownership will then automatically migrate to the site where it’s needed.
One more key benefit of ScaleOut GeoServer Pro is that it lets applications efficiently access objects that have slowly changing contents (such as product descriptions, schedules, and portfolio lists) without making repeated WAN accesses. Sites that are configured for bi-directional replication have immediate access to replicas when just reading but not updating remote objects. Other sites can be configured to maintain local copies of remote objects (called “proxies”) that can periodically poll for updates using a configurable timeout. This minimizes WAN accesses while allowing applications to track changes in objects stored at remote sites.
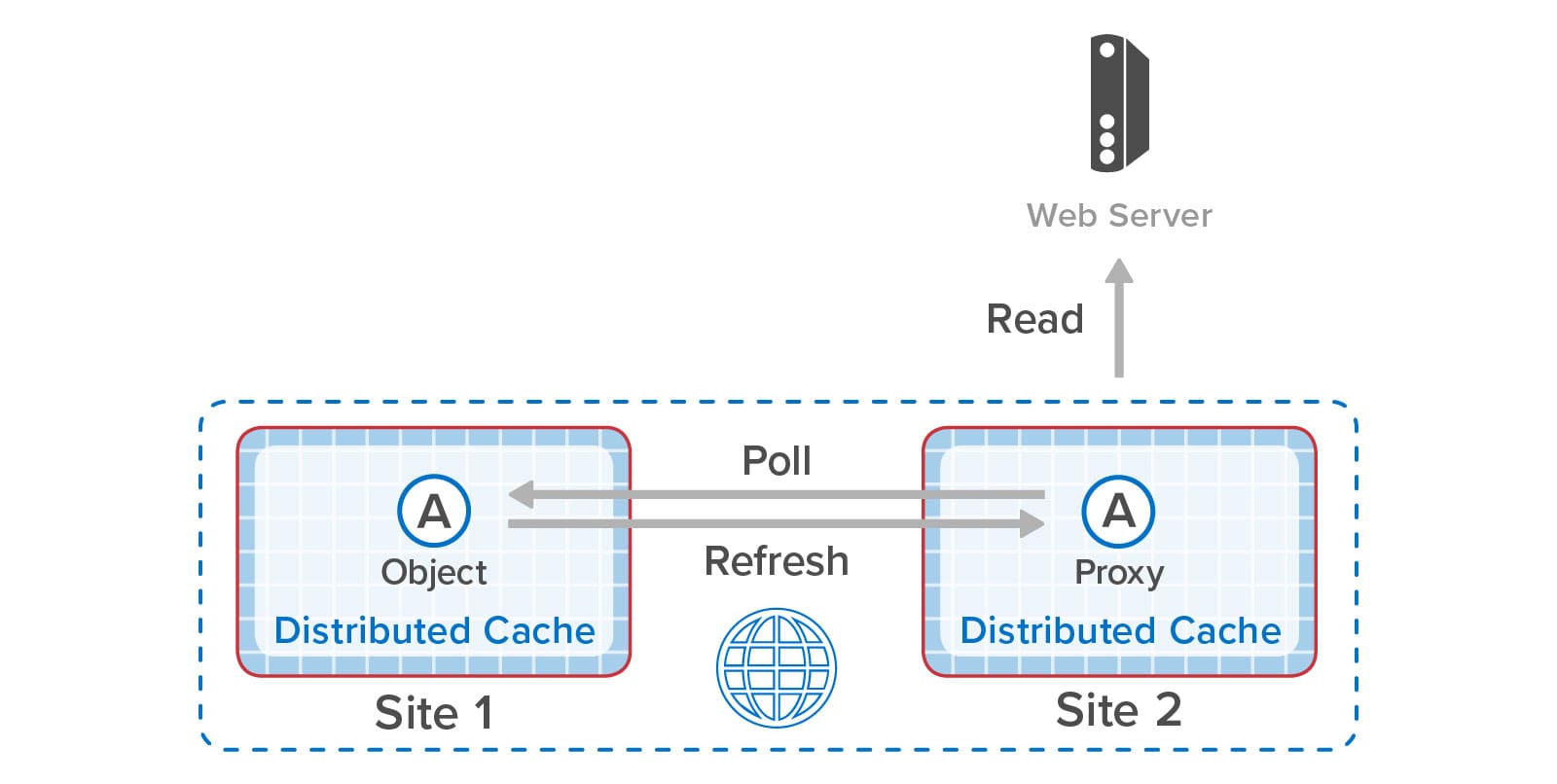
To illustrate how all of these features can work together, the following diagram shows two sites on the west coast of the U.S. configured for bi-directional replication and synchronized access along with additional “satellite” sites in other states that are periodically polling to read data held in the “live” data centers:
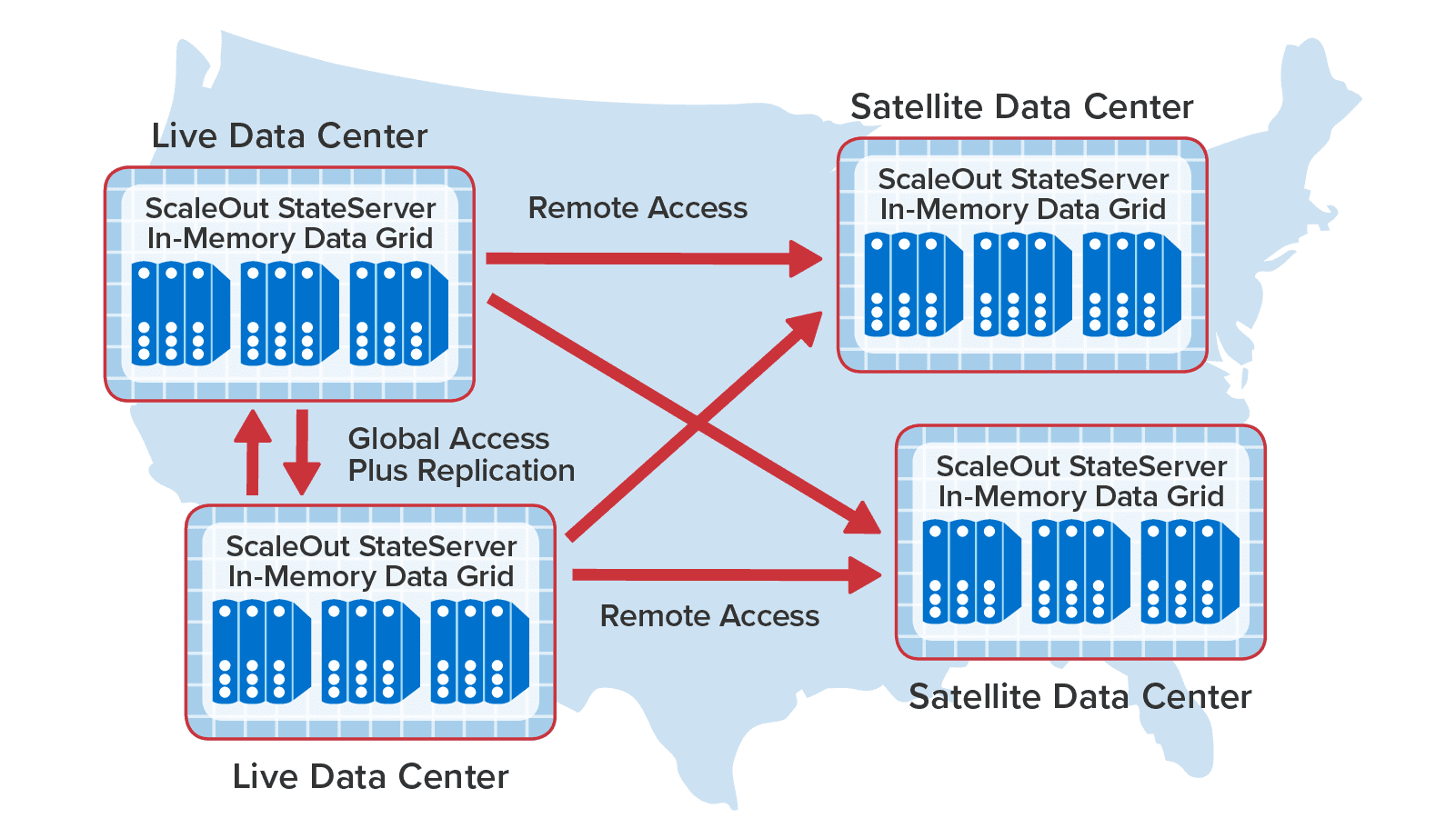
With its advanced capabilities for combining data replication with synchronized access, ScaleOut GeoServer Pro takes a leadership position among commercial in-memory data grids by enabling applications to seamlessly access and update objects replicated across data centers. This solves a long-standing challenge for applications that actively maintain mission-critical data at multiple sites and further extends the power of in-memory data grids to manage fast-changing business data.

Dr. William L. Bain is the founder and CEO of ScaleOut Software, which has been developing software products since 2003 designed to enhance operational intelligence within live systems using scalable, in-memory computing technology. Bill earned a Ph.D. in electrical engineering from Rice University. With over a 40-year career focused on parallel computing, he has contributed to advancements at Bell Labs Research, Intel, and Microsoft, and holds several patents in computer architecture and distributed computing.