Automatic Cluster Management
Stop Tracking Hashlots and Manually Load-Balancing Redis Clusters
Developers need to focus on developing applications, and system administrators are too busy to track the intricacies of a distributed caching architecture, like hashslots, shards, and replicas. To maximize ease of use, especially during membership changes and network outages, ScaleOut In-Memory Database’s cluster architecture was designed to fully automate management.
Users just need to deploy one ScaleOut In-Memory Database service process on each server (“node”) in a cluster; ScaleOut In-Memory Database takes care of the rest. The service processes work together to manage all aspects of cluster operations, including hashslots. They automatically create a Redis database with all 16K Redis hashslots and distribute the hashslots across the cluster’s nodes to achieve optimal load-balancing. The service processes automatically migrate hashslots between nodes when servers are added or removed or after recovery from server failures. They also maintain replicas for all hashslots on different nodes to ensure that data is never lost if a server fails or suffers a network outage.
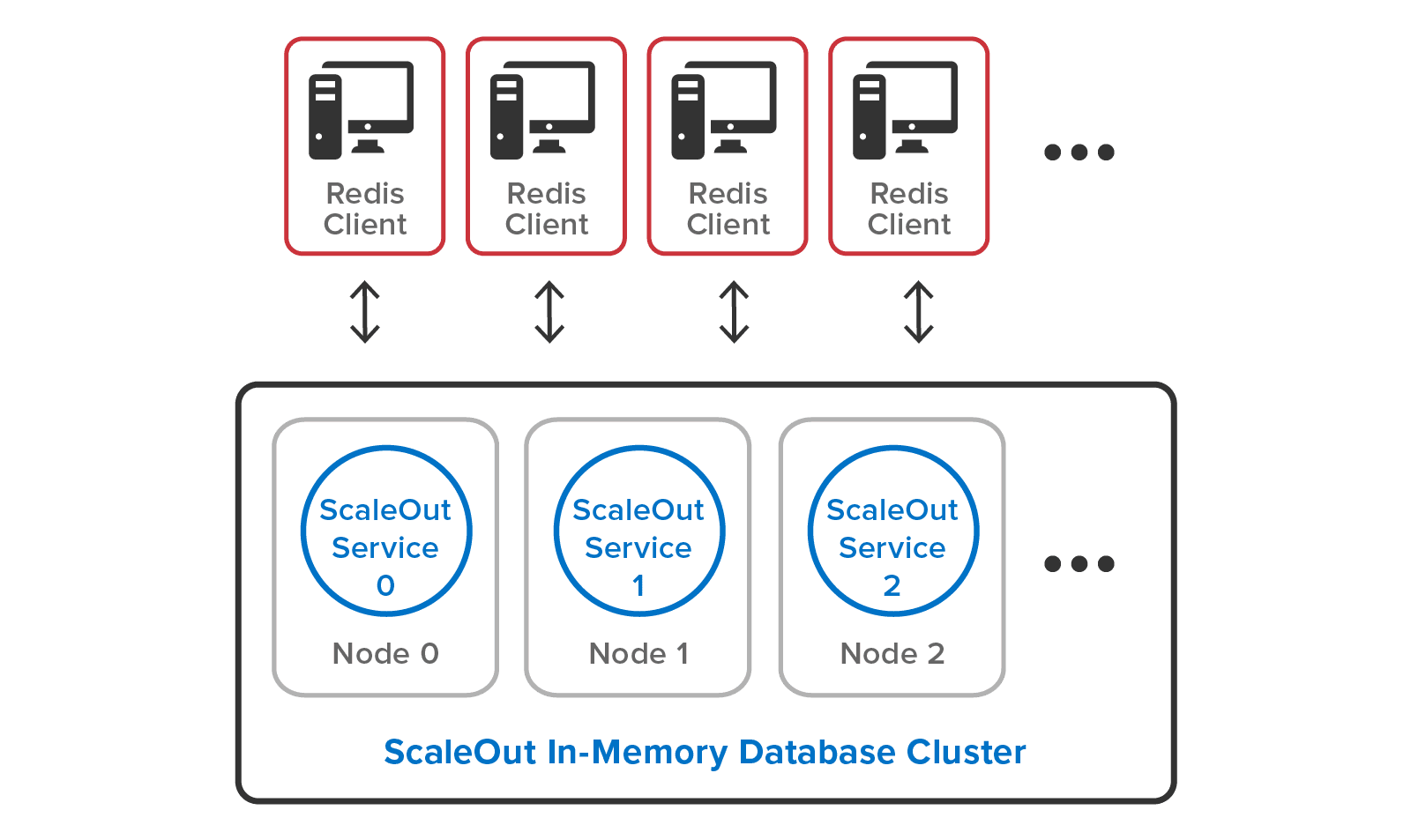
Redis clients can connect to any ScaleOut In-Memory Database server in a cluster using the standard RESP protocol. Most popular Redis client libraries then internally obtain the mapping of hashslots to servers using either the CLUSTER SLOTS or CLUSTER NODES commands and then direct Redis access requests to the appropriate ScaleOut server.
The following diagram shows Redis clients connecting to a ScaleOut In-Memory Database cluster:
Unlike when configuring open-source Redis clusters, you can start with one node and add more nodes as your throughput and availability demands grow. Most enterprise deployments will use at least two nodes to provide data replication and protect against server failures. Here’s an example of adding a node to a ScaleOut In-Memory Database cluster:
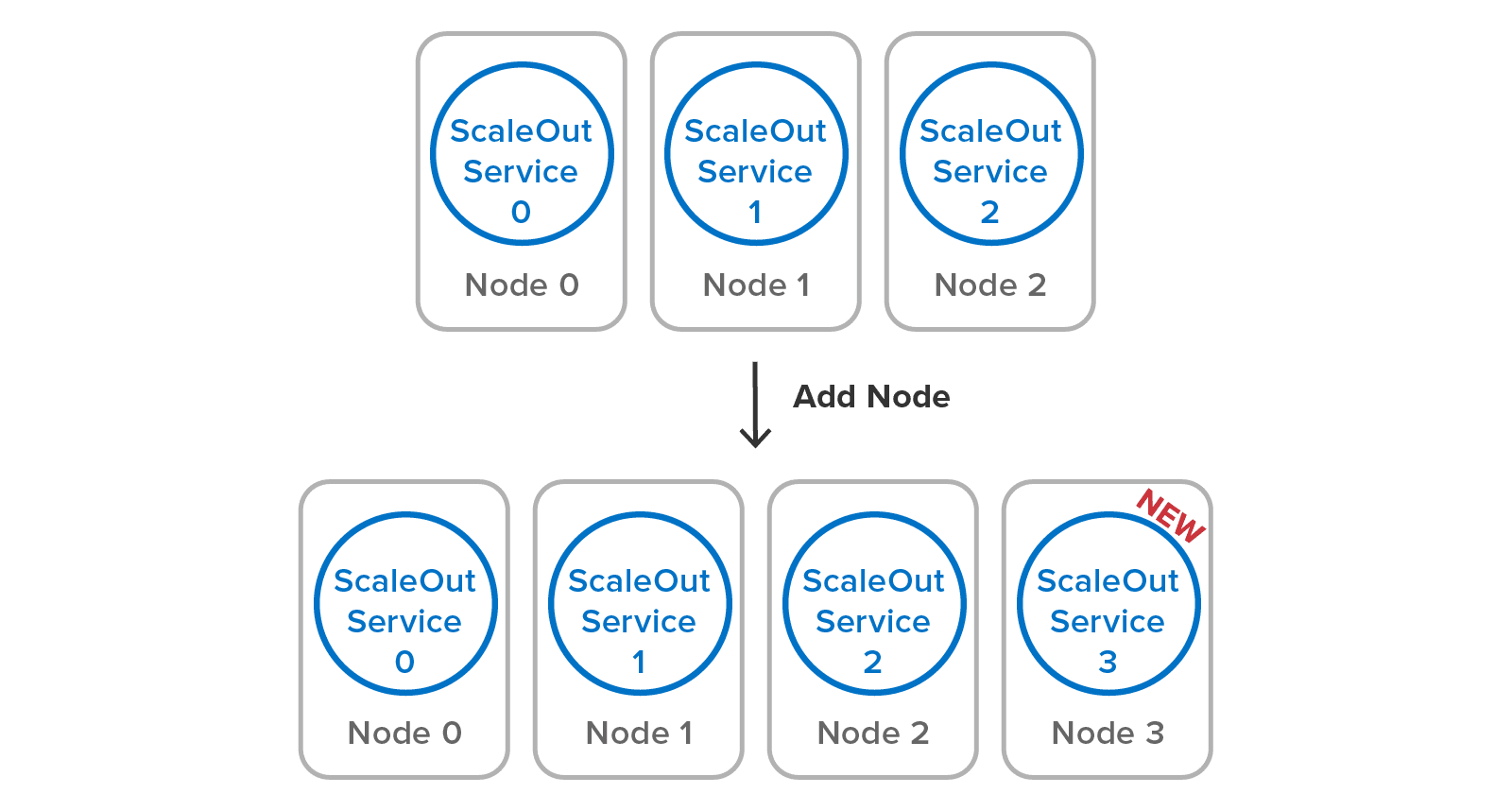
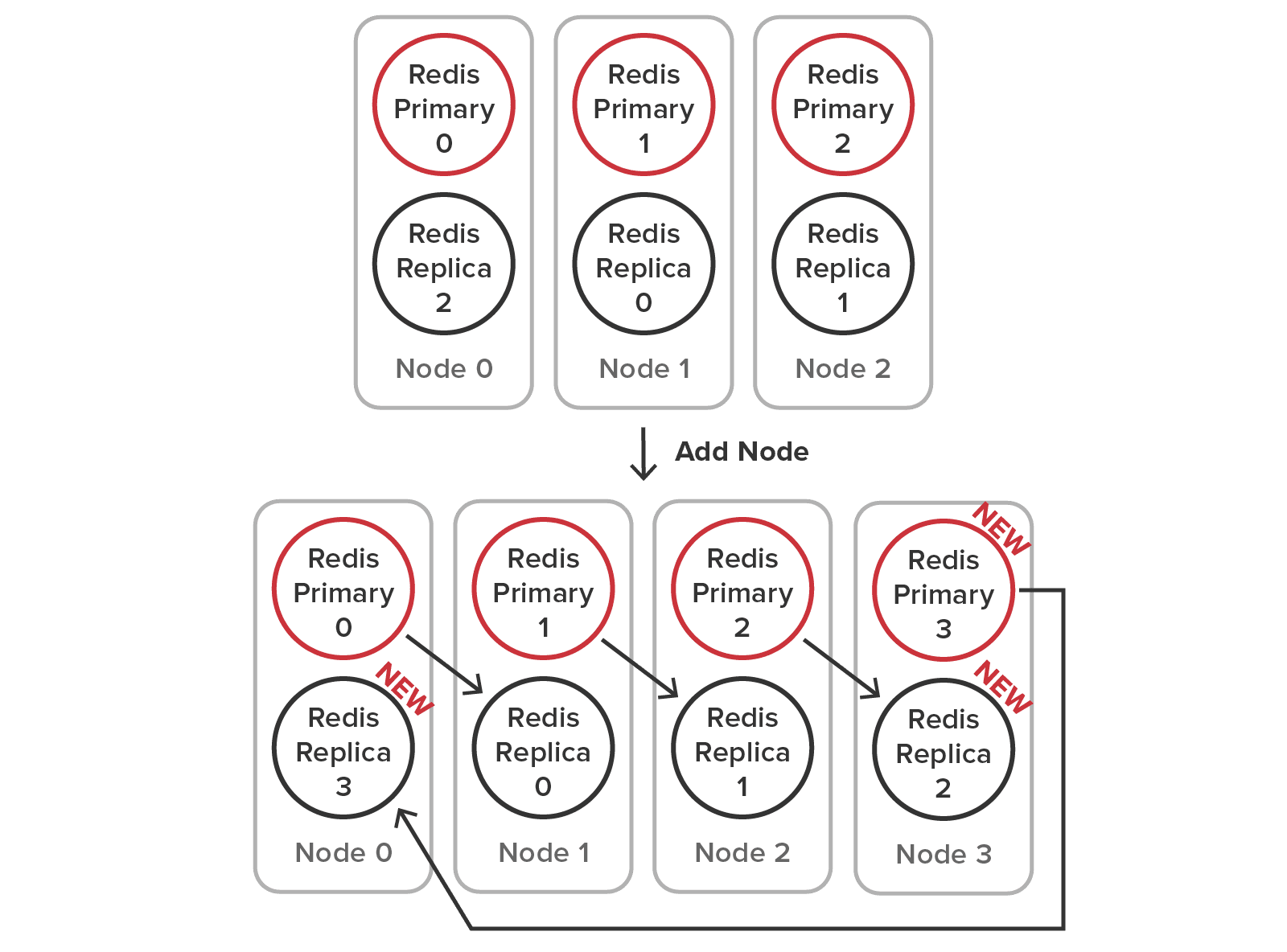
You just add one service process per node, and ScaleOut In-Memory Database takes care of the rest. There’s no need to create primary and replica shards and reconfigure existing shards, as would be needed in an open-source Redis cluster. Note how existing replica 2 has to be migrated to a different node to maintain a balanced workload when adding a node in a Redis cluster:
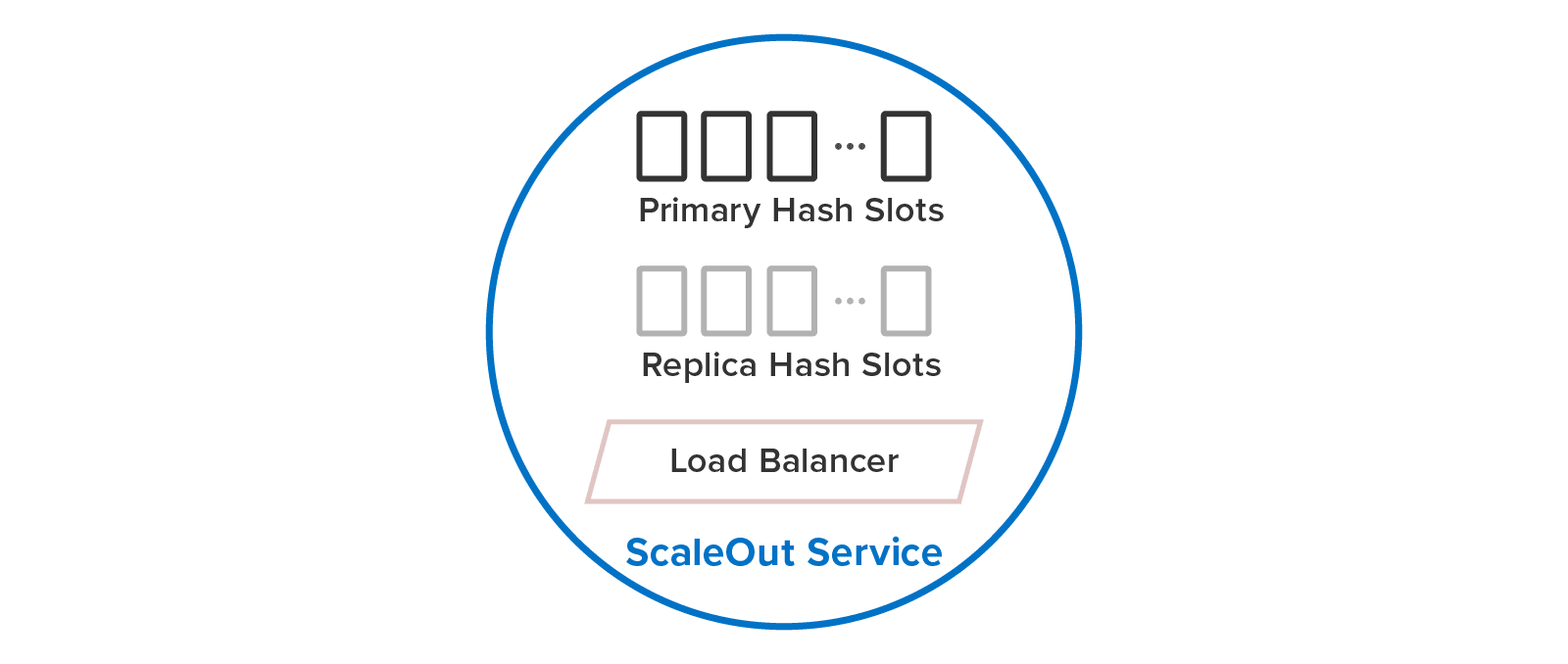
ScaleOut In-Memory Database hosts both primary and replica hashslots within its service process and handles all aspects of load-balancing when there are changes to the cluster’s membership:
For example, the following diagram shows how ScaleOut In-Memory Database automatically redistributes the hashslots across two servers when a second server is added to a single-server cluster:
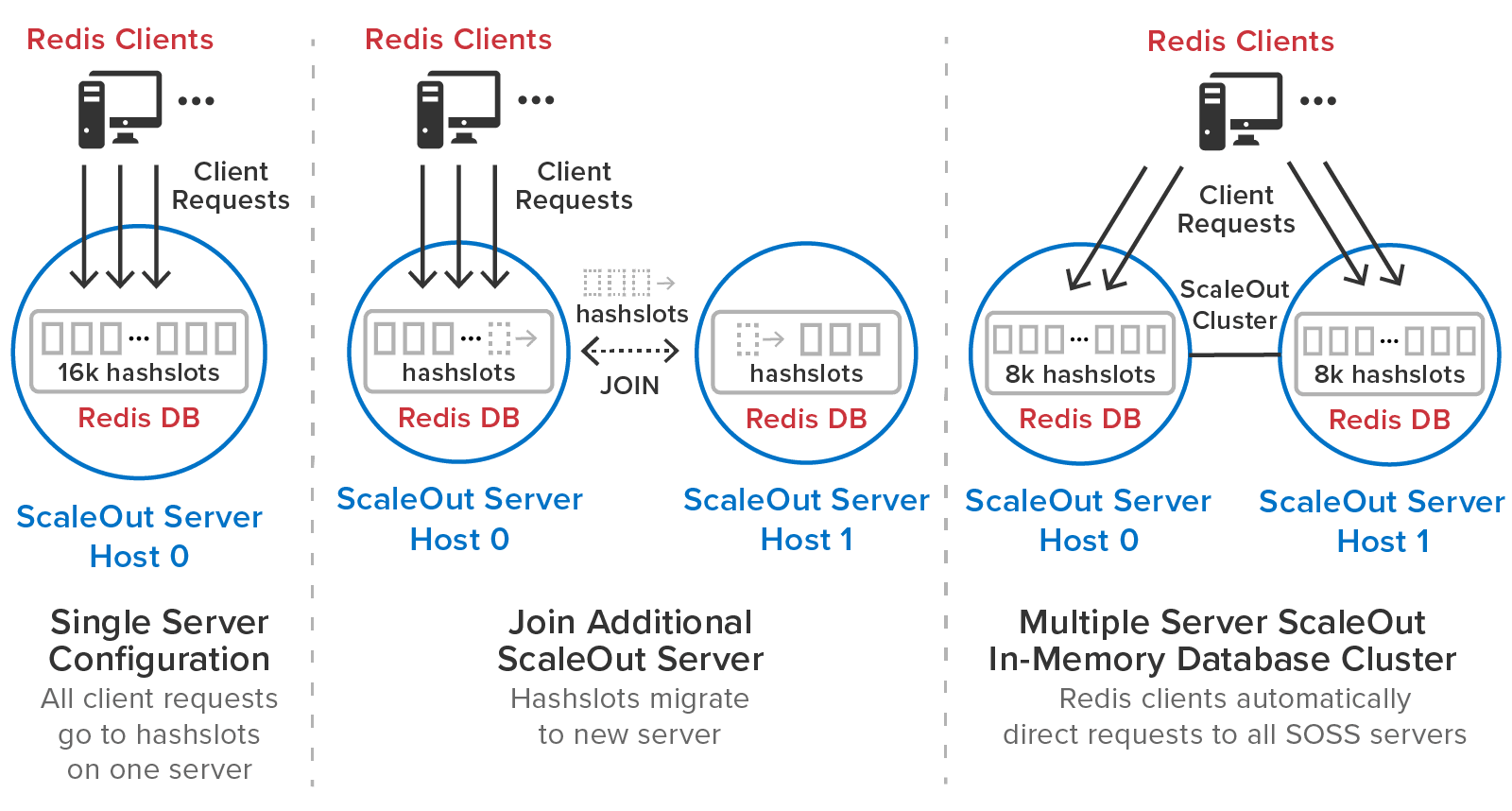
For each hashslot, ScaleOut In-Memory Database maintains at least one replica on a separate node. For example, in the above diagram showing a two-node cluster, both nodes have copies of each other’s hashslots to ensure full redundancy. When additional servers are added, ScaleOut In-Memory Database automatically redistributes both the primary and replica hashslots to maintain both load-balance and redundancy.
ScaleOut In-Memory Database uses a coherent cluster membership with built-in, adaptive heart-beating that adjusts to the speed of the network. When it detects a missing server due to a failure or network outage, it automatically “self-heals” by creating a new cluster membership, promoting and duplicating replicas as needed, and rebalancing the workload on the surviving servers. It also detects and recovers from network subnetting (sometimes called a “split brain” configuration).