Powerful Stream-Processing Model
What is the Digital Twin Model?
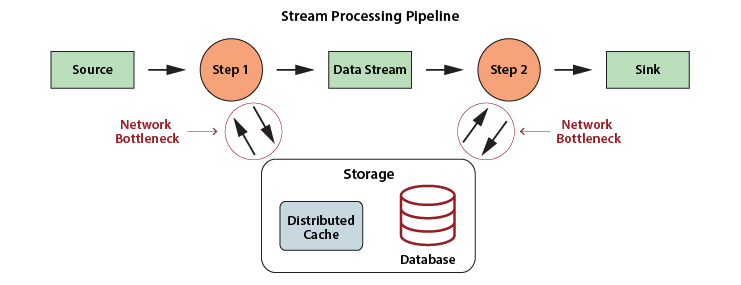
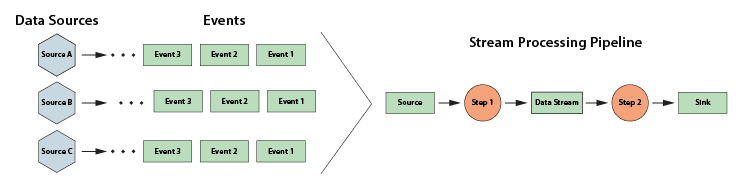
Traditional stream-processing and complex event processing systems have focused on extracting interesting patterns from incoming data with stateless applications. While these applications maintain state information about the data stream itself, they don’t generally make use of information about the dynamic state of data sources. For example, if an IoT application is attempting to detect whether data from a temperature sensor is predicting the failure of a medical freezer, it typically just looks at patterns in the temperature readings, such as sudden spikes or a continuously upward trend, without regard to the freezer’s usage or service history.
The following diagram depicts a typical stream processing pipeline processing events from many data sources:
Imagine if the stream-processing application for medical freezers could instantly access relevant information about each freezer’s specific model, service history, environmental conditions, and usage patterns. This would give its predictive analytics algorithm much richer context in which to analyze incoming temperature readings, leading to more informed predictions in real time about possible impending failures with fewer false alarms.
The digital twin model offers an answer to this challenge. While this term was coined for use in product life cycle management, it was recently popularized for IoT because it offers key insights into how state data can be organized within stream-processing applications for maximum effectiveness. In particular, it suggests that applications implement a stateful model of the physical data sources that generate event streams, and that the application maintain separate state information for each data source.
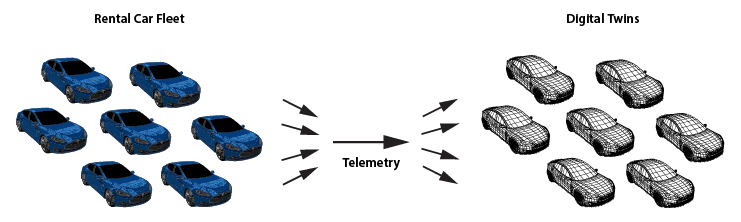
For example, using the digital twin model, a rental car company can track and analyze telemetry from each car in its fleet with digital twins with detailed knowledge about each car’s rental contract, the driver’s demographics and driving record, and maintenance issues. With this information it could, for example, alert managers when a driver repeatedly exceeds the speed limit according to criteria specific to the driver’s age and driving history or otherwise deviates from the rental contract. All of this leads to deeper and more timely insights on telemetry received from the vehicles:
The digital twin model provides an intuitive approach to organizing state data, and, by shifting the focus of analysis from the event stream to the data sources, it potentially enables much deeper introspection than previously possible. With the digital twin model, an application can conveniently track all relevant information about the evolving state of physical data sources and then analyze incoming events in this rich context to provide high quality insights, alerting, and feedback.
Digital twin models add value in almost every imaginable stream-processing application. They enable real-time streaming analytics that previously could only be performed in offline, batch processing. Here are a few examples:
- They help IoT applications do a better job of predictive analytics when processing event messages by tracking the parameters of each device, when maintenance was last performed, known anomalies, and much more.
- They assist healthcare applications in interpreting real-time telemetry, such as blood-pressure and heart-rate readings, in the context of each patient’s medical history, medications, and recent incidents, so that more effective alerts can be generated when care is needed.
- They enable ecommerce applications to interpret website clickstreams with the knowledge of each shopper’s demographics, brand preferences, and recent purchases to make more targeted product recommendations
In summary, the digital twin model provides a powerful organizational tool that refocuses stream-processing on the state of data sources instead of just the data within event streams. This additional context magnifies the developer’s ability to implement deep introspection and represents a new way of thinking about stateful stream-processing and real-time streaming analytics.
Digital Twins Are Just Objects
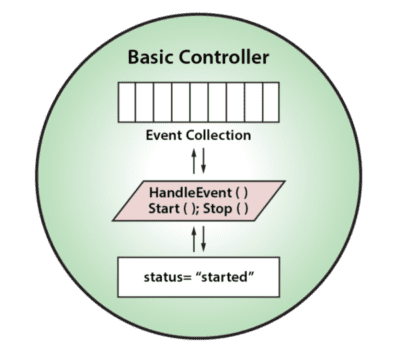
Beyond providing a powerful semantic model for stateful stream-processing, digital twins also offer advantages for software engineering because they can take advantage of well understood object-oriented programming techniques. A digital twin can be implemented as a data class which encapsulates both state data (including a time-ordered event collection) and methods for updating and analyzing that data. Analytics methods can range from simple sequential code to machine learning algorithms or rules engines. These methods also can reach out to databases to access and update historical data sets.
As illustrated in the following diagram, a digital twin can receive event messages from data sources (or other digital twins). It also can receive command messages from other digital twins or applications. In turn, it can generate alert messages to applications and feedback messages (including commands) to data sources. Having all of this contextual data immediately available to assist in analyzing event messages enables better, faster decision-making than previously possible:
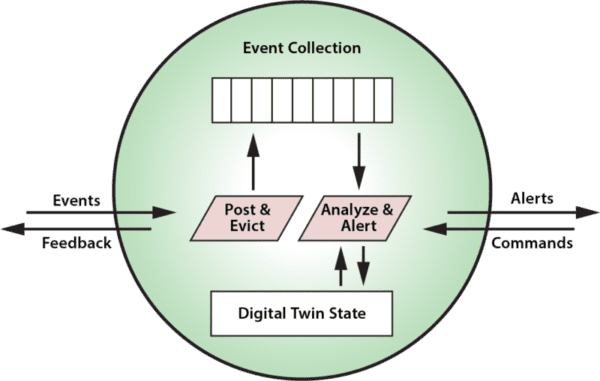
The granularity of a digital twin can encompass a model of a single sensor or that of a subsystem comprising multiple sensors. The application developer makes choices about which data (and event streams) are logically related and need to be encapsulated in a single entity for analysis to meet the application’s goals.
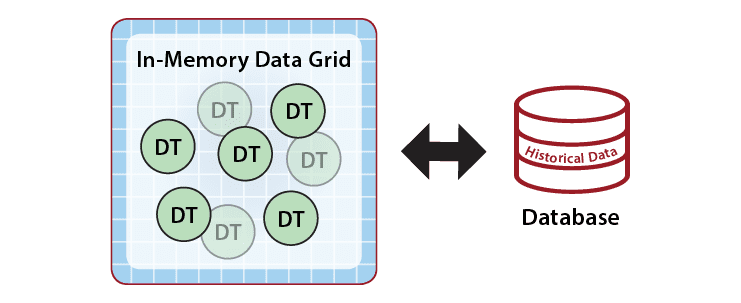
Although the in-memory state of a digital twin consists of only the event and state data needed for real-time processing, an application optionally can reference historical data from external database servers to broaden its context if needed, as shown below.
Building a Hierarchy of Digital Twins
Digital twin models can simplify the implementation of stream-processing applications for complex systems by organizing them into a hierarchy at multiple levels of abstraction, from device handling to strategic analysis and control. By partitioning an application into a hierarchy of digital twins, code can be modularized and thereby simplified with a clean separation of concerns and well-defined interfaces for testing.
For example, consider an application that analyzes telemetry from the components of a wind turbine. This application receives telemetry for each component and combines this with relevant contextual data, such as the component’s make, model, and service history, to enhance its ability to predict impending failures. As illustrated below for a hypothetical wind turbine, the stream-processing system correlates telemetry from three components (blades, generator, and control panel) and delivers it to associated digital twin objects, where event handlers analyze the telemetry and generate feedback and alerts:
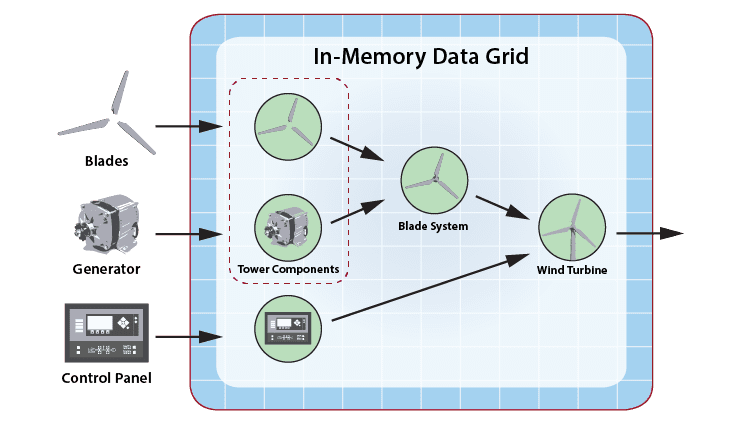
Taking advantage of the hierarchical organization shown above, digital twins for the blades and generator could feed telemetry to a higher-level digital twin model called the Blade System that manages the rotating components within the tower and their common concerns, such as avoiding over-speeds, while not dealing with the detailed issues of directly managing these two components. Likewise, the digital twin for the blade system and the control panel feed telemetry to a yet higher-level digital twin model which coordinates overall operations and generates alerts as necessary.
Building and Running Digital Twin Models
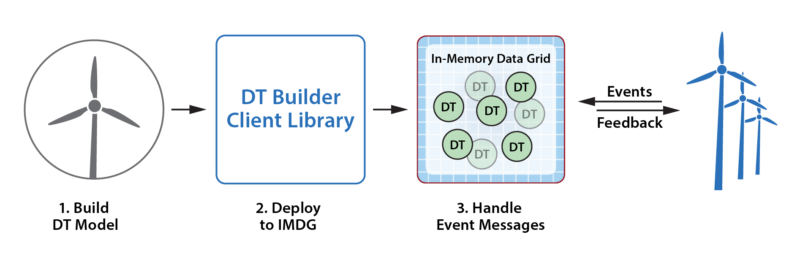
The ScaleOut Digital Twin Builder software toolkit enables developers to easily build digital twin models of data sources and deploy them to ScaleOut StreamServer for execution. The toolkit’s goal is to dramatically simplify the construction of these models by hiding the details of their implementation, deployment, connection to data sources, and management within ScaleOut StreamServer’s in-memory data grid (IMDG).
The toolkit includes class definitions in Java and C# for defining digital twin models in a form that can be deployed to ScaleOut StreamServer. It also includes APIs for deploying them on ScaleOut StreamServer so that instances of each model (one per data source) can receive and analyze incoming messages.
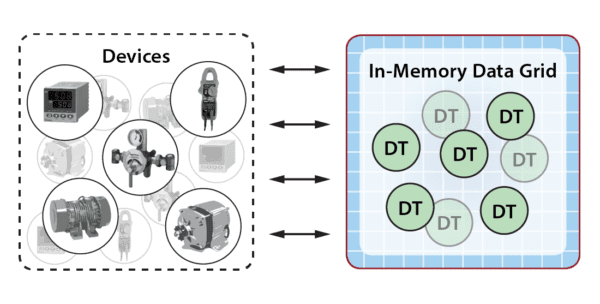
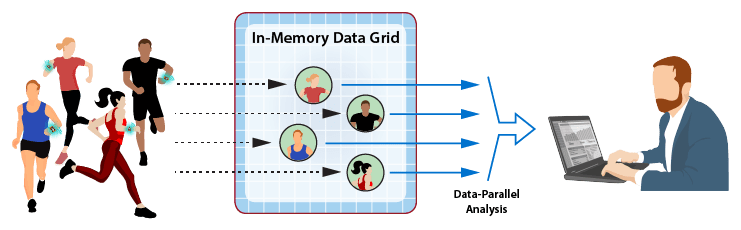
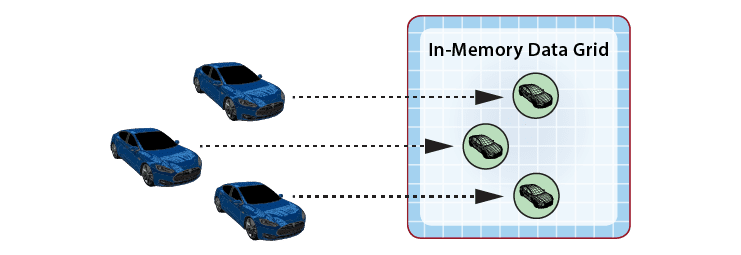
As messages arrive from data sources, ScaleOut StreamServer automatically creates an instance of a digital twin model within its IMDG as needed for each physical data source. It then correlates incoming messages from each data source for delivery to the associated instance of a digital twin model, as depicted in the following diagram for a fleet of rental cars. In many applications, the IMDG can host thousands (or more) digital twins to handle the workload from its data sources.
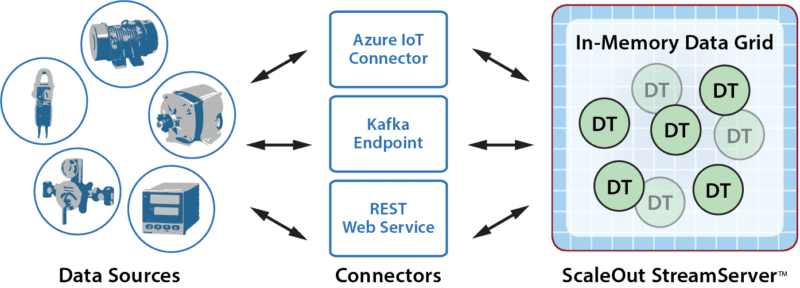
Using the ScaleOut Digital Twin Builder API Libraries, an application can create connections to Azure IoT Hub, Kafka, and REST as illustrated in the following diagram. These connections deliver event messages from data sources to digital twin models and return alerts and commands back to data sources from these models.
As part of event-processing, digital twins can create alerts for human attention and/or feedback directed at the corresponding data source. In addition, the collection of digital twin objects stored in the IMDG can be queried or analyzed using ScaleOut StreamServer’s data-parallel APIs to extract important aggregate patterns and trends. For example, in the rental car application, data-parallel analytics could allow a manager to query the compute the maximum excessive speeding for all cars in a specified region. These data flows are illustrated in the following diagram:
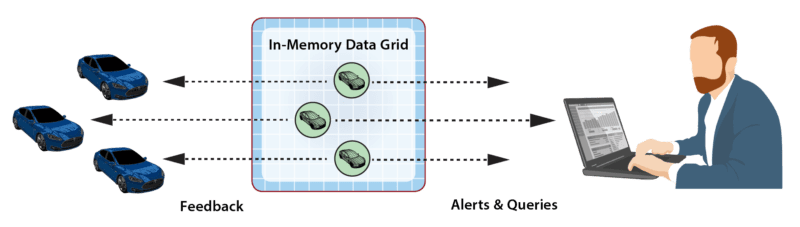
What makes ScaleOut StreamServer’s IMDG an excellent fit for hosting digital twin models is its ability to transparently host both state information and application code for thousands of digital twins within a fast, highly scalable, in-memory computing platform and then automatically direct incoming events to their respective digital twins within the grid for processing. These two key capabilities enable a breakthrough new approach to stateful stream-processing.
Automatic Event Correlation
ScaleOut StreamServer automatically correlates incoming messages from each data source for delivery to its respective digital twin. This simplifies application design by eliminating the need to pick out relevant messages from the event pipeline for analysis.
Immediate Access to State Information
By providing each digital twin’s message processing code immediate access to state information about the data source, applications have the context they need for deep introspection in real time — without having to access external databases or caches.