As we saw in a previous blog, the digital twin model popularized by Gartner provides a conceptual breakthrough for stateful stream-processing and opens the door to a new way of analyzing event streams. Whether the application is in IoT, financial services, logistics, medical systems, or mobile apps, this model offers a new technique enabling deeper introspection on streaming data than previously possible.
The secret to the power of the digital twin model is its focus on organizing real-time data by the data source to which it corresponds. What this means is that all event messages from each data source are correlated into a time-ordered collection, which is associated with both dynamic state information and historical knowledge of that data source. This gives the stream-processing application a rich context for analyzing event messages and determining what actions need to be taken in real time.
For example, consider an application which tracks a rental car fleet to look for drivers who are lost or driving recklessly. This application can use the digital twin model to correlate real-time telemetry (e.g., location, speed) for each car in the fleet and combine that with data about the driver’s contract, safety record with the rental car company, and possibly driving history. Instead of just examining the latest incoming events, the application now has much more information instantly available to judge when and whether to signal an alert.
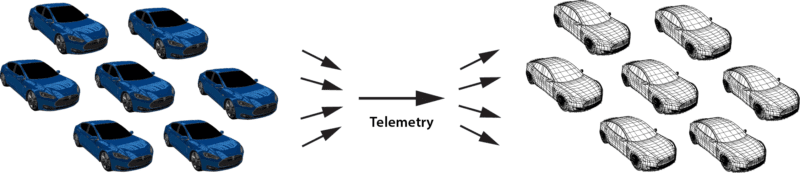
When implementing a stateful stream-processing application using the digital twin model, an object-oriented approach offers obvious leverage in managing the data and event processing associated with this model. For each type of data source, the developer can create a data type (object “class”) which describes the event collection, real-time state data, and analysis code to be executed when a new event message arrives. Instances of this data type then can be created for each unique data source as its digital twin for stream-processing. Here is a depiction of a digital twin object and its associated methods:
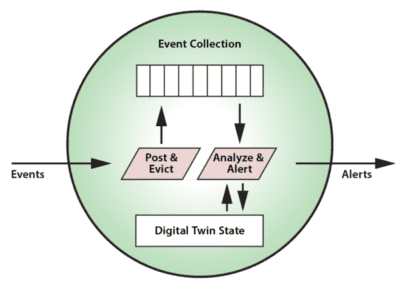
This object-oriented approach makes an in-memory data grid (IMDG) with integrated in-memory computing, (e.g., ScaleOut StreamServer™) an excellent stream-processing platform for real-time digital twin models. IMDGs have a long history dating back almost two decades. They were originally created as middleware software to host large populations of fast-changing data objects, such as ecommerce session-state and shopping carts, in memory instead of database servers, thereby speeding up access. An IMDG implements a software-based, key-value store of serialized objects that spans a cluster of commodity servers (or cloud instances). Its architecture provides cost-effective scalability and high availability, while hiding the complexity of distributed in-memory storage from the applications which use them. It also can take full advantage of a cluster’s computing power to run application code within the IMDG — where the data lives — to maximize performance and avoid network bottlenecks.
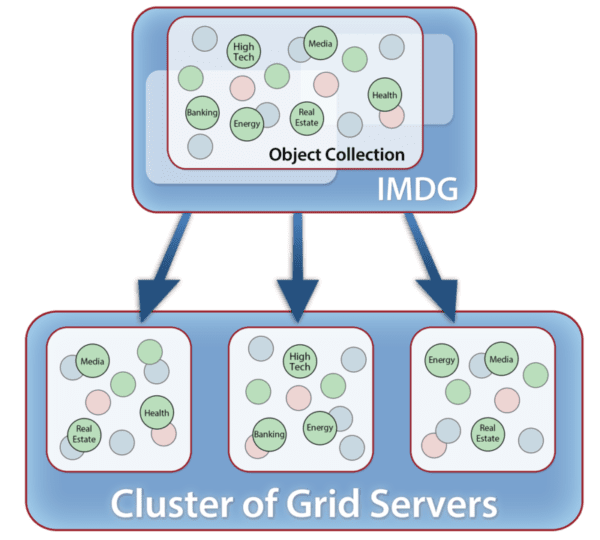
Using an example from financial services, the following diagram illustrates an application’s logical view of an IMDG as a collection of objects (stock sectors in this case) and its physical implementation as in-memory storage spanning a cluster of servers:
It should now be clear why IMDGs offer a great way to host digital twin models and perform stateful-stream processing. An IMDG can store instances of a digital twin model and scale its storage capacity and event-processing throughput by adding servers to hold many thousands of instances as needed for all the data sources. The grid’s key-value storage model automatically correlates incoming event messages for the corresponding digital twin instance based on the data source’s identifying key. When the grid delivers an event to its digital twin, it then runs the model’s application code for event ingestion, analysis, and alerting in real time.
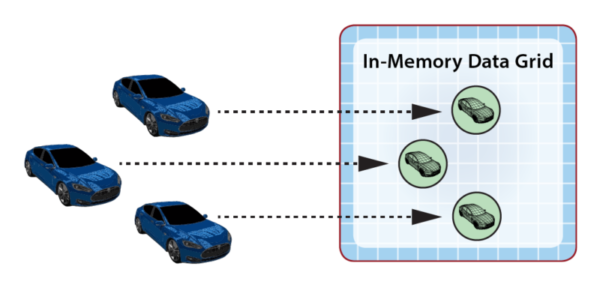
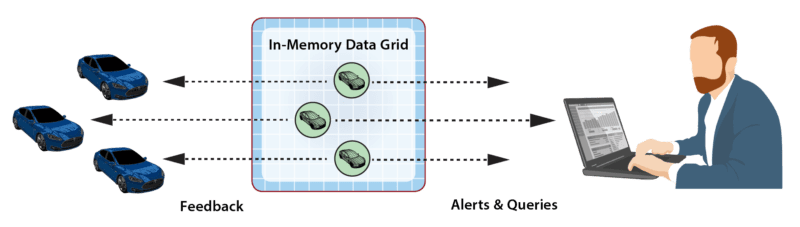
As an example, the following diagram illustrates the use of an IMDG to host digital twin objects for rental cars. The arrows indicate that the IMDG directs events from each car to its corresponding digital twin for event-processing.
As part of event-processing, digital twins can create alerts for human attention and/or feedback directed at the corresponding data source. In addition, the collection of digital twin objects stored in the IMDG can be queried or analyzed using data-parallel techniques (e.g., MapReduce) to extract important aggregate patterns and trends. For example, the rental car application could alert managers when a driver repeatedly exceeds the speed limit according to criteria specific to the driver’s age and driving history. It also could allow a manager to query the status of a specific car or compute the maximum excessive speeding for all cars in a specified region. These data flows are illustrated in the following diagram:
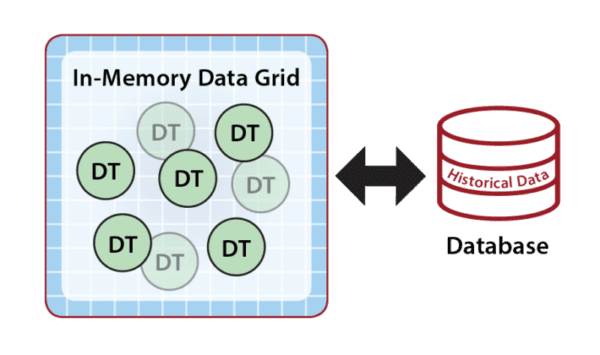
Because they are hosted in memory, digital twin models can react very quickly to incoming events, and the IMDG can scale by adding servers to keep event processing times fast even when the number of instances (objects) and/or event rates become very large. Although the in-memory state of a digital twin is restricted to the event and state data needed for real-time processing, the application can reference historical data from external database servers to broaden its context, as shown below. For example, the rental car application could access driving history only when incoming telemetry indicates a need for it. It also could store past events in a database for archival purposes.
What makes an IMDG an excellent fit for stateful stream-processing is its ability to transparently host both the state information and application code within a fast, highly scalable, in-memory computing platform and then automatically direct incoming events to their respective digital twin instances within the grid for processing. These two key capabilities, namely correlating events by data sources and analyzing these events within the context of the digital twin’s real-time state information, give applications powerful new tools and create an exciting new way to think about stateful stream-processing.

Dr. William L. Bain is the founder and CEO of ScaleOut Software, which has been developing software products since 2003 designed to enhance operational intelligence within live systems using scalable, in-memory computing technology. Bill earned a Ph.D. in electrical engineering from Rice University. With over a 40-year career focused on parallel computing, he has contributed to advancements at Bell Labs Research, Intel, and Microsoft, and holds several patents in computer architecture and distributed computing.