Access Data Fast
In-Memory, Object-Oriented Storage for Fast Access
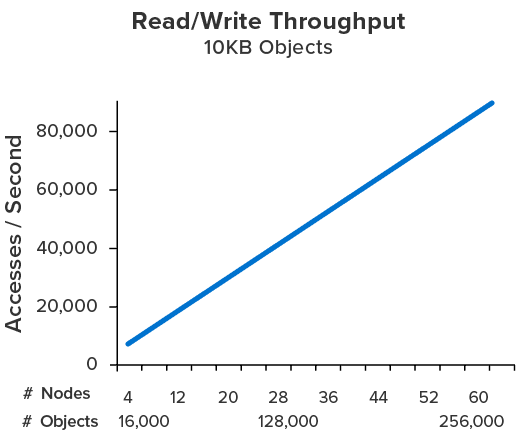
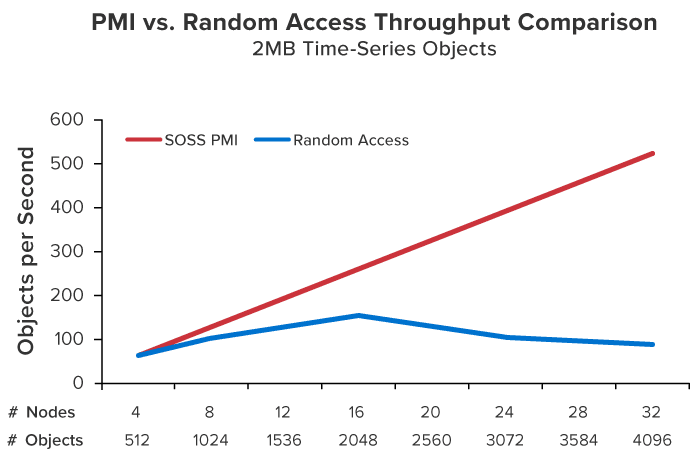
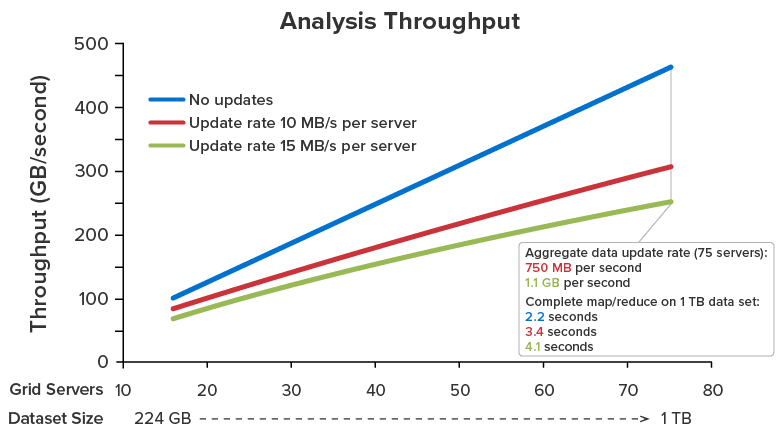
Delivering fast data access requires keeping data close to where it is used while enabling sharing by multiple clients and scaling to handle large workloads. Unlike database servers and file systems, which are designed for long term data storage and “mostly read” access, ScaleOut’s in-memory data grid (IMDG) was specifically created to handle fast-changing data with minimum latency.
To ensure fast data access — and, at the same time, simplify application design — IMDGs directly integrate with business logic using an object-oriented representation for stored data. This avoids the complex transformations needed to use data storage providers (such as relational databases), and it fully leverages object-oriented languages (such as Java, C#, and C++) in which business logic typically is written. Straightforward APIs for creating, reading, updating, and deleting objects accessed by unique, shareable keys minimize access time and simplify integrating an IMDG into business logic. Together, these characteristics ensure fast access, and they streamline development.
Client Caching for Near “In Process” Latency
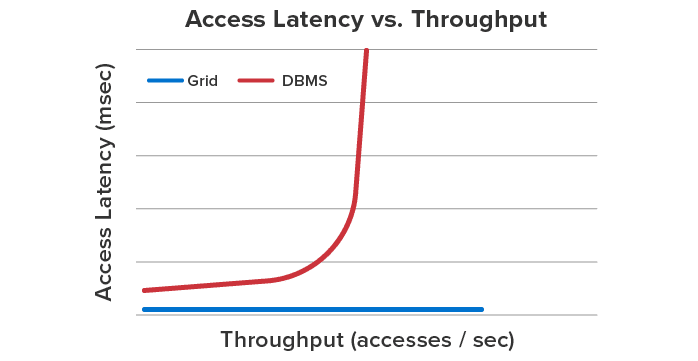
IMDGs use “out-of-process” storage to keep their services securely separated from client applications and to facilitate scaling by adding servers. To mitigate the serialization and network data transfer overheads associated with out-of-process storage, ScaleOut’s IMDG incorporates client caching within its API libraries. This results in fast read access times that are very close to the performance of an “in-process” store and significantly better than access times for all “out-of-process” stores, such as database servers. For example, the chart below shows 6X faster access time for ScaleOut’s IMDG in comparison to a database server.
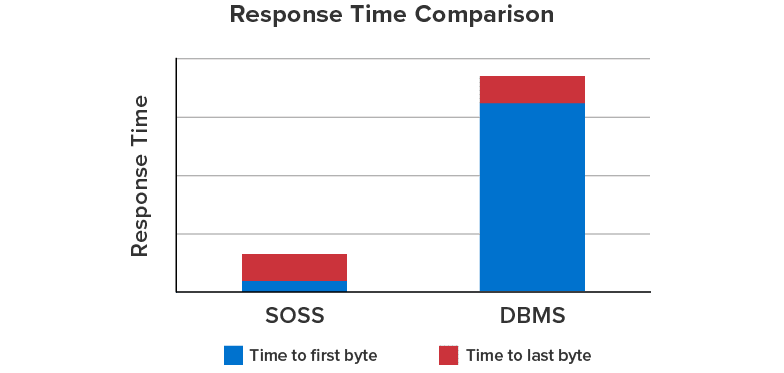
Comparison of Read Access Time for ScaleOut’s IMDG vs. a Database Server