
ScaleOut’s Battle-Tested Clustering Technology Give It Key Advantages Over Redis®* in Ease of Use and Performance
By William L. Bain and Bryce C. Klinker
Breaking news: ScaleOut Software has announced a community preview of support for Redis clients in ScaleOut StateServer. Learn more here.
Distributed caching technology first hit the market in about 2001 with the introduction of Tangosol Coherence and has been evolving ever since. Designed to help applications scale performance by eliminating bottlenecks in accessing data, this distributed computing technology stores live, fast-changing data in memory across a cluster of inexpensive, commodity servers or virtual machines. The combination of fast, memory-based data storage and throughput scaling with multiple servers results in consistently fast access and update times for growing workloads, such as e-commerce, financial services, IoT device tracking, and other applications.
ScaleOut Software introduced its distributed caching product, ScaleOut StateServer® (SOSS), in 2005 and has made continuous enhancements over the last 16 years. While the single-server version of Redis was released in 2009 by Salvatore Sanfilippo, clustering support was first added in 2015. These two products embody highly different design goals. SOSS was designed as an integrated distributed caching architecture incorporating transparent throughput scaling and high availability using data replication with the goals of maximizing performance, ease of use, and portability across operating systems. In contrast, according to M. Russo, Redis was conceived as a single-server, data-structure store to improve the performance of a real-time data analytics product. (Beyond just storing strings or opaque objects, a data-structure store also implements various data types, such as lists and sorted sets.) Clustering was added to Redis’ single-server architecture after 4 years to provide a way to scale.
As background for the following discussion, it’s important to review some key concepts. Most distributed caches use a key/value storage model that identifies stored objects using string keys. To distribute objects across multiple servers in a cluster, a distributed cache typically maps keys to hash slots, each of which holds a subset of objects. The cache then distributes hash slots across the servers and moves them between servers as needed to balance the workload; this process is called sharding. A group of hash slots running on a single server (called a node here) can either be a primary or replica. Clients direct updates to the target hash slot on a primary node, which replicates the update to one or more replica nodes for high availability in case the primary node fails.
Ease of Use
The differences in design goals of the two technologies have led to very different impacts on users. To maximize ease of use, SOSS automatically creates and manages hash slots for the user, including primaries and replicas. Using a built-in load-balancer, each service internally manages a subset of both primary and replica hash slots, as illustrated below. Users just create a single SOSS service process on every node, and these service processes discover each other and distribute the hash slots among themselves to balance the workload. They also automatically handle all aspects of recovery after a node fails.
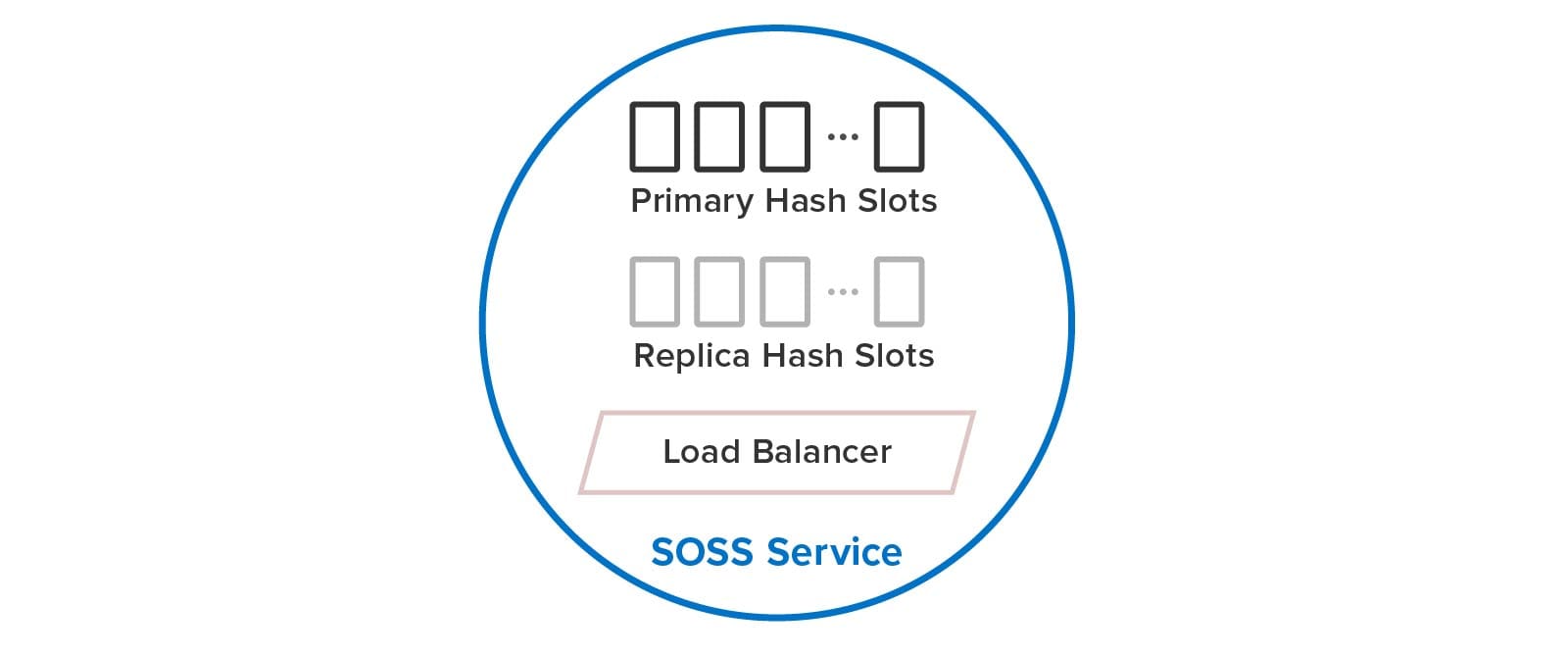
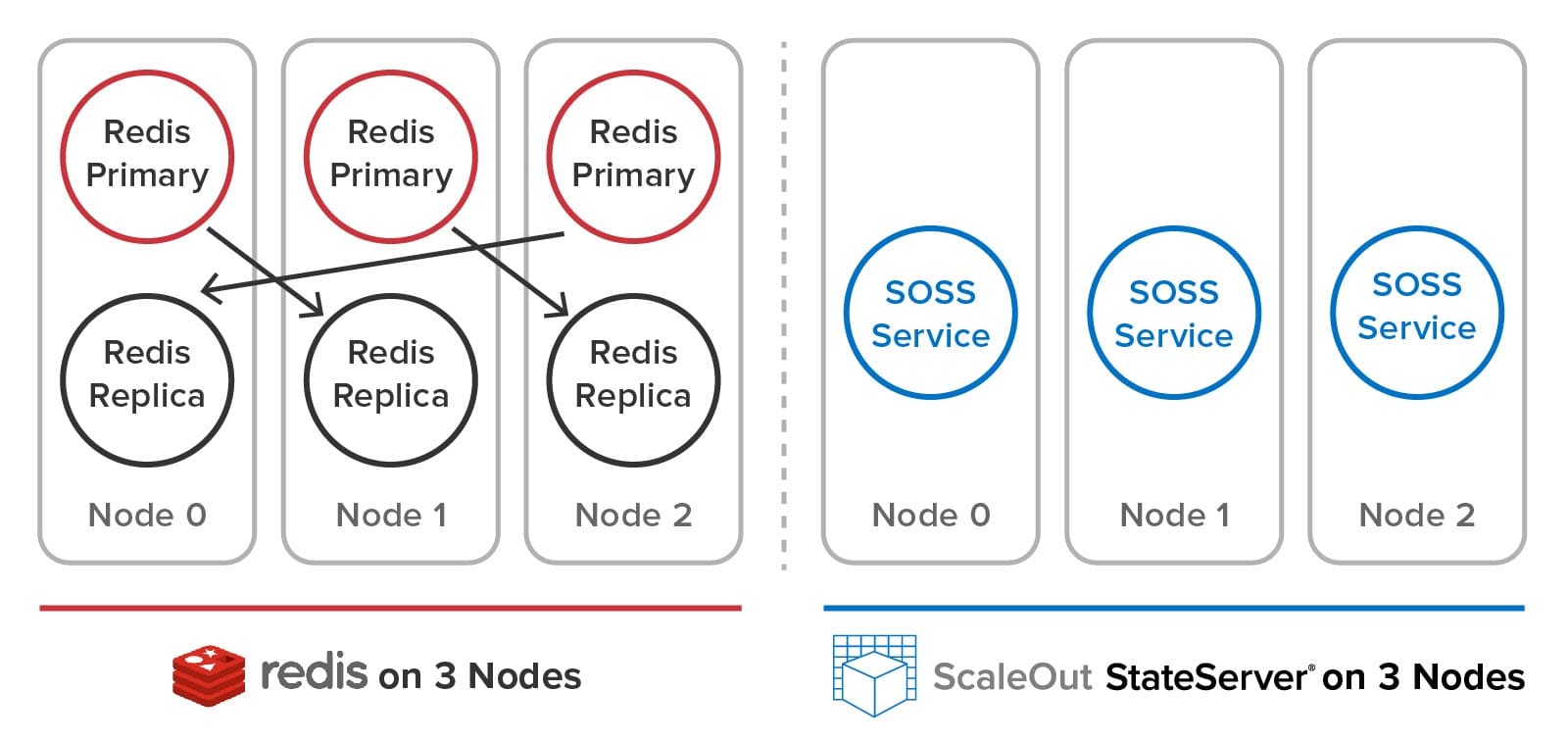
In contrast, Redis users create separate service processes on each node for primary and replica hash slots and must manually distribute the hash slots among the primaries. (Unlike SOSS, a 1-node or 2-node Redis cluster is not allowed.) As we will see below, users must perform a complex set of manual actions when adding and removing nodes and to heal and rebalance the cluster after a node fails. The following diagram illustrates the difference between Redis and SOSS in the user’s view of the cluster:
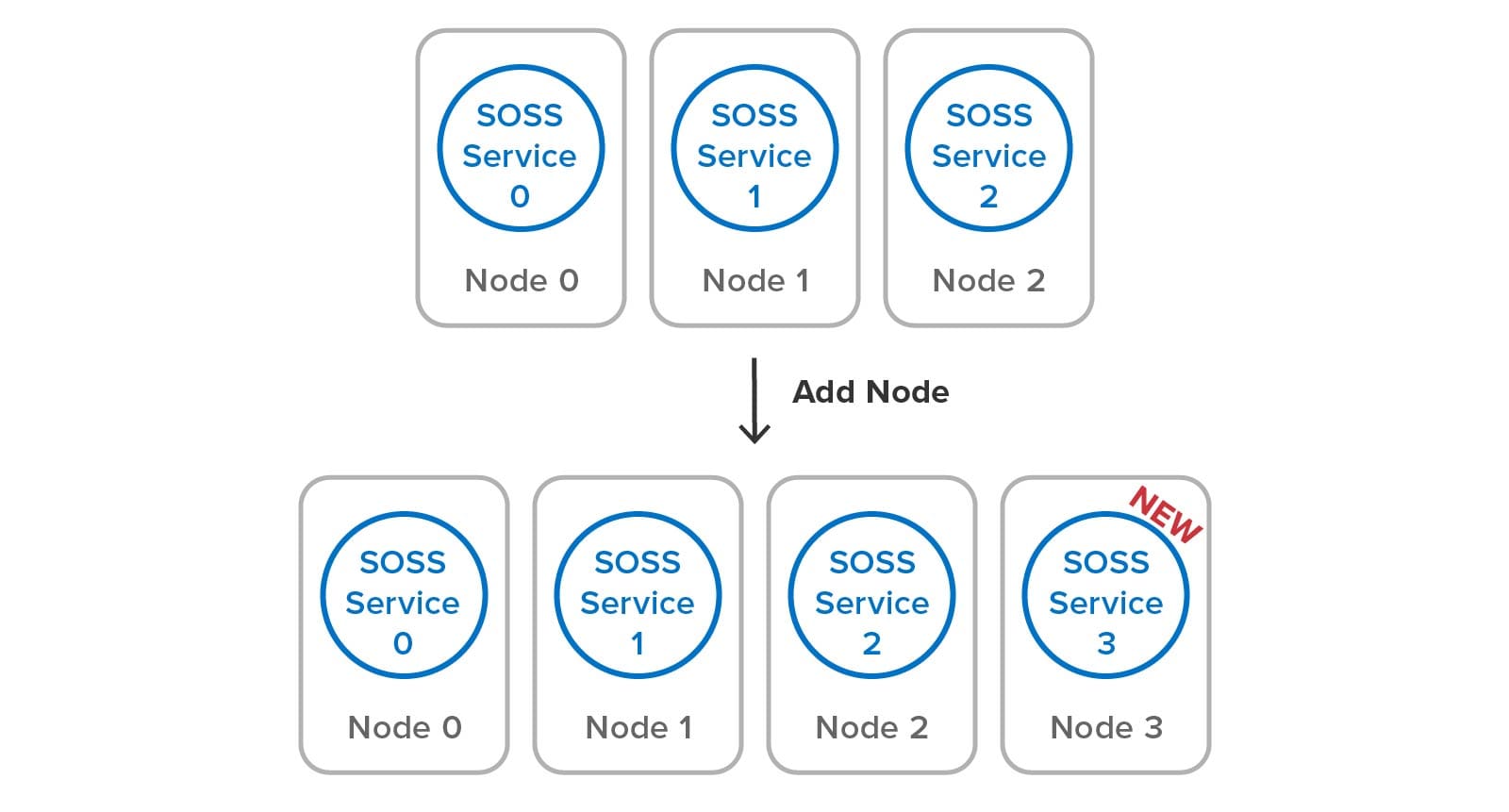
Adding a Node to the Cluster Using SOSS
To illustrate how SOSS’s built-in mechanisms for managing hash slots, load-balancing, failure detection, and self-healing simplify cluster management, let’s look at the steps needed to add a node to the cluster. When using SOSS, the user just installs the service on a new node and clicks a button in the management console to join the cluster. Using multicast discovery (or optional host list if multicast is not available), the service process automatically receives primary and replica hash slots and starts handling its portion of the workload. The following diagram shows the addition of a fourth node to a cluster:
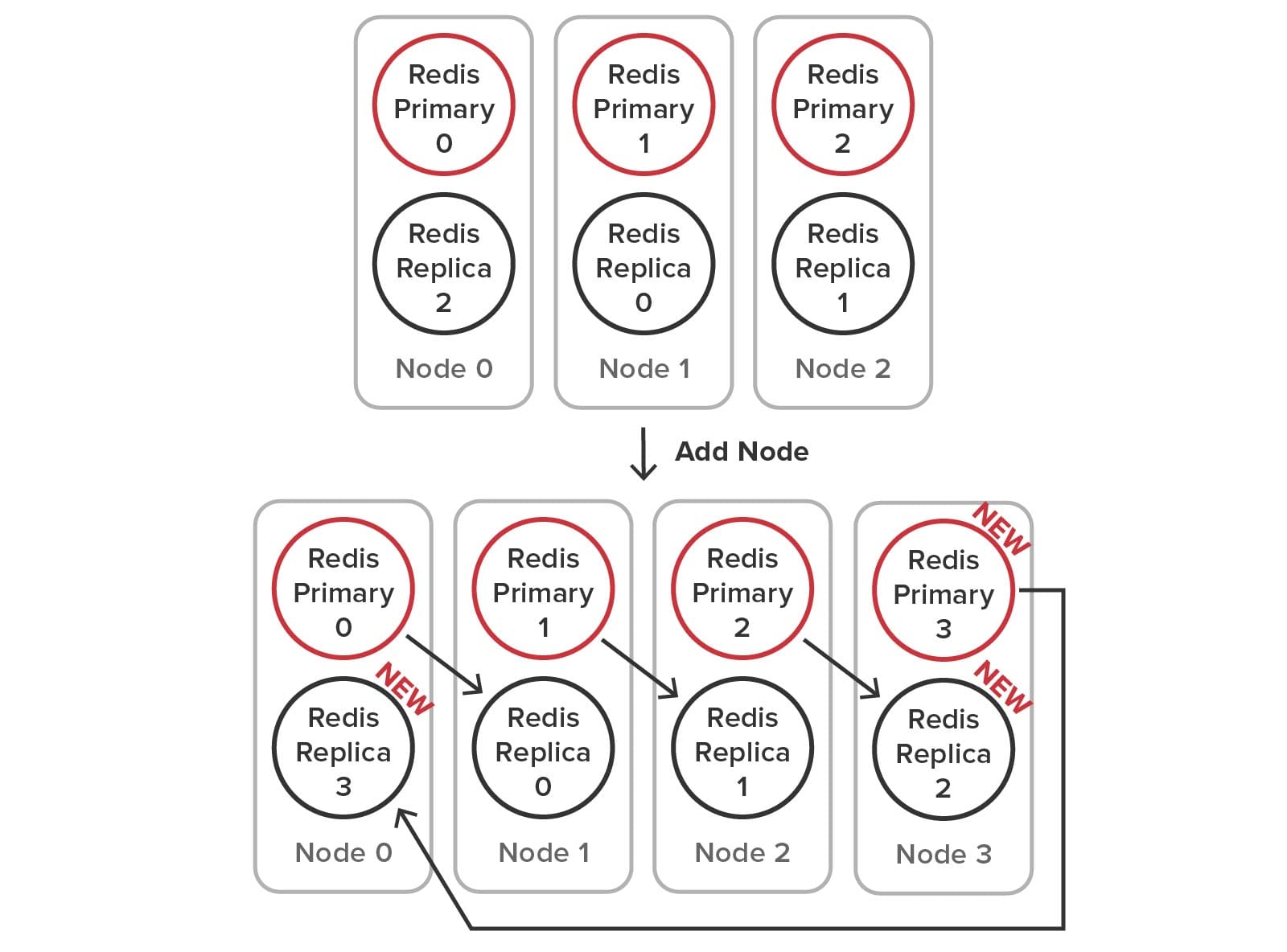
Adding a Node to the Cluster Using Redis
Because Redis requires the user to manage the creation of primary and replica service processes (sometimes called shards) and the management of hash slots, many more steps must be performed to add a node to the cluster. To accomplish this, the user runs administrative commands that create the new processes, connect the primaries and replicas, move the replicas as necessary, and reallocate the hash slots among the nodes. The required configuration changes are illustrated below:
Here is an example of administrative steps required to make the configuration changes (using node 0’s IP and port as the bootstrap address for the new node):
// Start up a new replica redis-server instance on node 3 for primary 2:
redis-cli --cluster add-node host3Ip:replicaPort node0Ip:node0Port --cluster-slave
--cluster-master-id primary2NodeID
// Start up a new primary redis-server instance on node 3:
redis-cli --cluster add-node host3Ip:primaryPort existingIp:existingPort
// Connect to replica 2 on node 0 and modify it to replicate primary 3:
redis-cli -h replica2Ip -p -replica2Port > cluster replicate primary3NodeID
// Reshard the cluster by interactively moving hash slots from existing nodes to node 3:
redis-cli --cluster reshard existingIp:existingPort
> How many slots to move? 4096 //16384 / 4 = 4096
> What node to move slots to? primary3NodeID // (primary3NodeID returned by previous command)
> What nodes to move slots from? all
This process is complex, and it becomes more difficult to keep track of the distribution of hash slots with larger cluster memberships. Removing a node has comparable complexity.
Recovering After a Node Fails (SOSS and Redis)
SOSS’s service processes automatically detect and recover from the loss of a node. They use built-in, scalable, peer-to-peer heart-beating to detect missing node(s) and create a new, coherent cluster membership. Next, they promote replica hash slots to primaries on the surviving nodes, create new replicas for self-healing, and rebalance the workload across the nodes.
Redis does not implement a coherent cluster membership and does not provide automatic self-healing and recovery. Each Redis node sends heartbeat messages to random other nodes to detect possible failures, and the cluster uses a gossip mechanism to declare that a node has failed. After that, its replica on a different node promotes itself to a primary so that the hash slots remain available, but Redis does not self-heal by creating a new replica for the hash slots. Also, it does not automatically redistribute the hash slots across the nodes to rebalance the workload. These tasks are left to the system administrator, who needs to sort out the needed configuration changes and implement them to restore a fully redundant, balanced cluster.
Performance Comparison
The different design choices between SOSS and Redis also lead to semantic and performance differences. To maximize ease of use for application developers, SOSS maintains all stored data with full consistency (to be more precise, sequential consistency), ensuring that it only serves the latest updates and never loses data after the failure of a single server (or two servers if multiple replicas are used). This design choice targets enterprise applications that need to ensure that the distributed cache always returns the correct data. To implement data replication across multiple replicas with the highest possible performance, SOSS uses a patented quorum algorithm.
In contrast, Redis employs an eventual consistency model with asynchronous replication. In general, this choice enables higher throughput because updates do not have to wait for replication to complete before responding to the user. It also enables potentially higher read throughput by serving reads from replicas even if they are not guaranteed to serve the latest updates.
Given these two design choices, it’s valuable to compare the throughput of the two distributed caches as nodes are added and the workload is simultaneously increased, as illustrated below. This technique evaluates how well the caches can scale their throughput by adding nodes to handle increasing workload; linear throughput scaling ensures consistently fast response times. (For a discussion of throughput scaling in distributed systems, see Gustafson’s Law.).
To perform an apples-to-apples throughput comparison of Redis 6.2 and SOSS 5.10, SOSS was configured to use eventual consistency (“EC”) when updating replicas. The performance of SOSS with full consistency (“FC”) was also measured. Tests were run for 3, 4, and 6 node clusters in AWS on m5.xlarge instances with 4 cores@2.5 Ghz, and 16GB RAM. The clients ran read/update pairs on 100K objects of sizes 2KB and 20KB to represent a typical web workload with a 1:1 read/update ratio. The results are as follows:
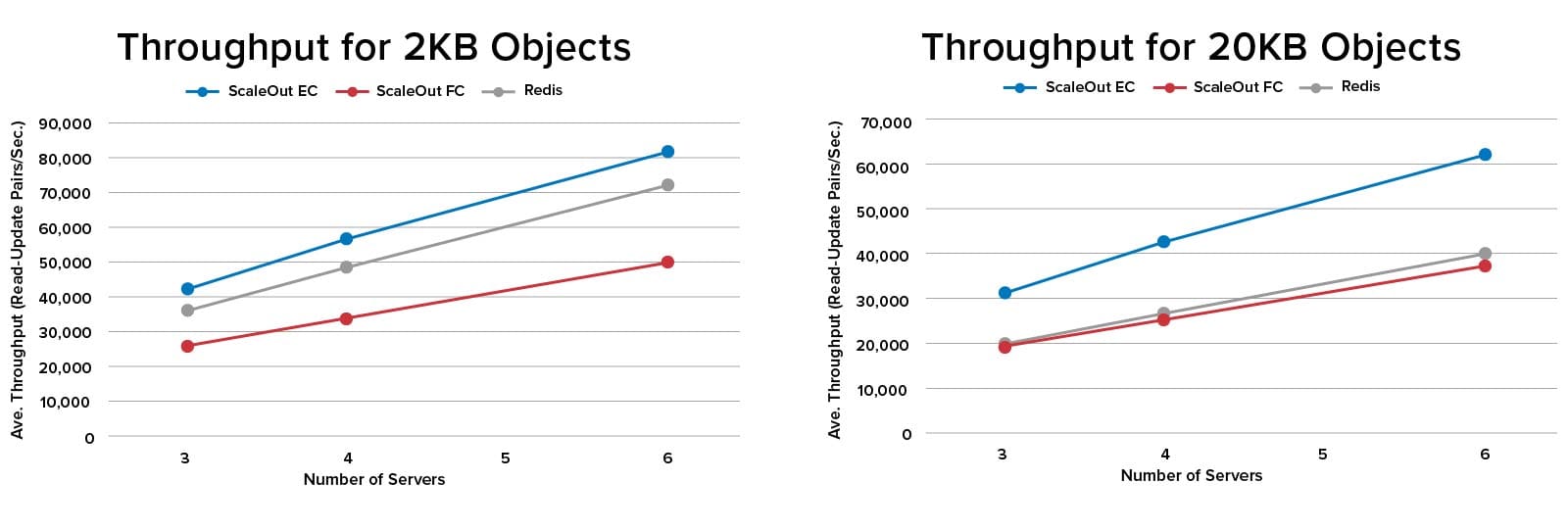
SOSS provided consistently higher throughput than Redis when eventual consistency was used to perform updates (the blue and gray lines in the charts). Running SOSS with full consistency (the red lines) resulted in lower throughput, as expected, since updates have to be committed at the replica before responding to the client instead of being performed asynchronously. However, both Redis and SOSS with full consistency delivered close to the same throughput for 20KB objects. This may be due to benefits of SOSS’s client-side caching, which eliminated unnecessary data transfers during reads.
Summing Up
Our comparison of SOSS and Redis shows the benefits of ScaleOut’s integrated clustering architecture. A key design goal for SOSS was to simplify the user’s workload by providing a unified, location-transparent data cache with built-in, fully automatic load-balancing and high availability. By hiding the inner workings of hash slots, heart-beating, replica placement, load-balancing, and self-healing, the application developer and systems administrator can focus on simply using the distributed cache instead of configuring its implementation. In our view, Redis’s approach of exposing these complex mechanisms to the user significantly steepens the learning curve and increases the user’s workload.
It might come as a surprise to learn that in the above benchmark testing, SOSS maintained a consistent performance advantage. We attribute this to ScaleOut’s approach of designing an integrated cluster architecture from the outset instead of adding clustering to a single server data store, as Redis did. This approach enabled design freedom at every step to eliminate distributed bottlenecks, and it led to extensive use of multithreading and internal data sharding within each service process to extract maximum performance from multi-core servers.
Lastly, SOSS demonstrates that the CAP theorem doesn’t really prevent the use of full consistency when building a scalable, distributed cache. For many enterprise applications, which demand data integrity at all times, this may be the better choice.
Learn more about how ScaleOut StateServer compares to Redis.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.

Dr. William L. Bain is the founder and CEO of ScaleOut Software, which has been developing software products since 2003 designed to enhance operational intelligence within live systems using scalable, in-memory computing technology. Bill earned a Ph.D. in electrical engineering from Rice University. With over a 40-year career focused on parallel computing, he has contributed to advancements at Bell Labs Research, Intel, and Microsoft, and holds several patents in computer architecture and distributed computing.