Real-time analytics offers enterprises the ability to examine “live,” fast-changing data within operational systems and obtain feedback in milliseconds to seconds. For example, a hedge fund in a financial services organization can track the effect of market fluctuations on its portfolios (“strategies”) of long and short equity positions in various market areas (high tech, real estate, etc.) and immediately identify strategies requiring rebalancing. As we have seen in previous blogs, the key to real-time performance, especially for growing workloads, is to use in-memory, data-parallel computing, which delivers scalable throughput and minimizes performance losses due to data motion. But how can we easily structure computations to take advantage of this “scale out” technology?
The Starting Point: Domain Decomposition
Going back to the 1980s, application developers realized that determining how to partition data so that each portion can be analyzed in parallel, a technique often called “domain decomposition,” is the fundamental design decision in data-parallel programming. Once this is accomplished, the domain can be parceled out among the servers within a computational cluster, and the analysis can proceed in parallel on all servers. The cluster speeds up the computation and also allows more servers to be added as the workload (i.e., the domain) grows in size.
The key to domain decomposition is determining which data within the state of an application to use as the domain for parallel analysis. In many cases, the domain is easy to identify, especially when the application is analyzing a physical entity. For example, in an earlier blog we saw how a climate simulation divides the atmosphere, land, and ocean into a grid of boxes which are analyzed independently at each time interval. Likewise, structural mechanics and fluid dynamics typically use grids that model physical systems.
The process of domain decomposition can be more challenging for applications whose data sets can be partitioned in different ways. Consider the hedge fund example above. Do we analyze the data by partitioning the stock symbols across the servers and then analyzing all strategies which hold a given stock? Alternatively, should we partition the strategies and analyze all positions within the strategy? Is there still another domain decomposition?
Minimize Data Motion: An Example in Financial Services
The best approach to choose usually is dictated by the need to minimize data motion. If a given decomposition induces data motion at each analysis step, this can kill performance while saturating the network. For example, if the hedge fund analysis partitions stock symbols, it would need to query all strategies affected by the stock symbol to obtain information needed to perform the analysis, and this requires substantial data motion for each stock symbol. (This assumes that the strategies as well as the stock symbols – and, in general, all data sets – are distributed across the cluster of servers performing the data-parallel computation, as is the case for data sets stored within an in-memory data grid (IMDG).
Instead, the computation could partition the strategies across the servers and analyze all strategies in parallel. In this case, it would need to query the latest stock prices for all positions within each strategy; this also induces data motion. In either case, if the strategies and stock prices are stored in separate data sets, unacceptable data motion will be incurred by the data-parallel computation.
However, if the stock prices for all relevant positions are kept up to date within the strategies instead of storing this data elsewhere, no data motion is needed to perform the data-parallel analysis, and maximum performance is achieved. Bearing in mind that multiple strategies maintain positions in a given stock, how can we efficiently update the strategies as price changes flow in from a market feed? The answer lies in leveraging data-parallel computation to both analyze and update the strategies. We can distribute a snapshot of price changes to all strategies at the start of each analysis and use this information to update each strategy’s positions prior to performing the analysis. This easily can be accomplished by tracking all price changes since the last analysis step and efficiently distributing them to the servers as part of the invocation mechanism for the analysis.
The following diagram illustrates how an IMDG can host a set of strategies and perform parallel analysis on the strategies while updating them with a live market feed containing snapshots of price changes. The analysis produces a stream of alerts to the trader (or to an automated trading system) for strategies that need rebalancing. In ScaleOut Analytics Server, the data parallel analysis can be implemented using a feature called parallel method invocation (PMI):
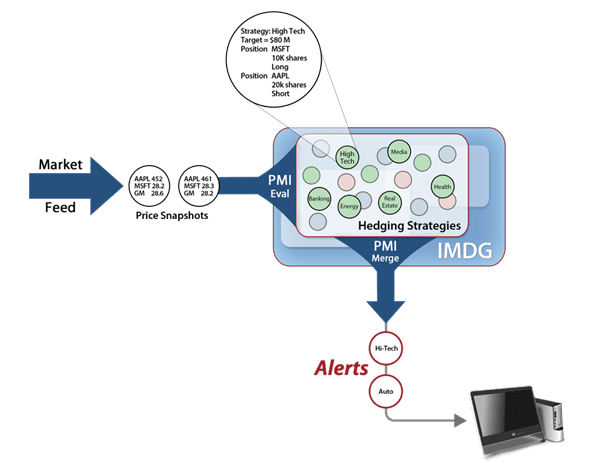
The net effect is that the hedge fund in real time can update its strategies and obtain alerts regarding positions that require rebalancing based on current market conditions. Take a look at this demo of a proof of concept implementation for 2K strategies tracking and analyzing a total of 40K positions using a cluster of four servers. This demo was implemented using a real-time Hadoop MapReduce engine implemented within ScaleOut hServer and delivered alerts within about 330 milliseconds (instead of more than 15 seconds for standard Hadoop).
Another Example: Inventory Reconciliation in E-Commerce
Consider another example of an e-commerce application that needs to reconcile orders and inventory in real time to avoid a shortfall in inventory. Orders flow into the system for a set of products (“SKUs”), and inventory changes flow into the system from several sources: orders to outside vendors are placed, products arrive at the warehouse, orders from customers are filled, defects are detected, etc. Especially with perishable goods, it’s vital to precisely track order commitments so that orders can be accurately filled (and customers stay happy).
Several different domain decompositions for reconciling orders to inventory could be used. Do we partition based on the orders, the inventory changes, or on some other basis? If we reconcile based on pending orders, we have to query the inventory changes for all items within each order, inducing substantial, performance-killing data motion. Likewise, if we partition the inventory changes, we have to query all orders that include a given inventory item, again inducing data motion.
To solve this problem, we can collect pending orders and inventory changes within their common SKUs and then use the SKUs to form a domain decomposition. As orders come into the system, we update the SKUs for all items within each order to track those orders. Likewise, as inventory changes flow in, we update the SKUs to maintain the latest inventory updates. This continuous process updates the SKUs on a real-time basis in a manner analogous to an ongoing database join operation. Now, a data-parallel analysis of the SKUs can reconcile all relevant orders and inventory changes for that SKU without causing data motion. This enables the cluster to perform a reconciliation across all SKUs in seconds instead of minutes.
The following diagram illustrates an IMDG hosting a collection of data representing SKUs that are being updated by incoming orders and inventory changes. The IMDG performs data-parallel reconciliation (“Eval”) of the SKUs and combines the results (“Merge”) while operations are ongoing:
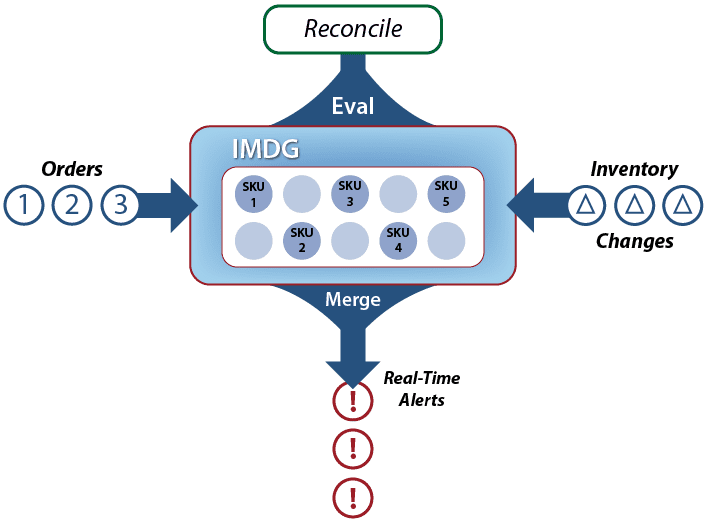
Note that in this example, we do not use the data-parallel invocation mechanism to perform updates to the application’s state as we did with the hedge fund example. Instead, individual order and inventory updates flow into the application on a continuous basis, and the data-parallel analysis is performed on the state information as it changes. In both cases, the integration of data-parallel analysis within an operational system handling live data demonstrates the value of real-time analytics: analysis results are continuously generated and fed back to the system to optimize its ongoing operations.
Using an IMDG to Host a Data-Parallel Application
Lastly, note that an IMDG serves as an ideal host for both the application’s state and the data-parallel analysis. By storing data in memory and distributing it across a cluster of servers, it can keep up with continuous updates and scale to handle growing workloads (while maintaining high availability) just by adding servers. And it can perform data-parallel analysis on domains of data distributed across the servers, leveraging the IMDG’s automatic load-balancing and avoiding data motion across the network during the analysis.
Interestingly, the object-oriented programming model supported by IMDGs helps us to structure, distribute, identify, query, and analyze domains that we construct for real time analysis. We will explore that in an upcoming blog.