The Challenge: Keeping Online Sites Fast
In this time of extremely high online usage, web sites and services have quickly become overloaded, clogged trying to manage high volumes of fast-changing data. Most sites maintain a wide variety of this data, including information about logged-in users, e-commerce shopping carts, requested product specifications, or records of partially completed transactions. Maintaining rapidly changing data in back-end databases creates bottlenecks that impact responsiveness. In addition, repeatedly accessing back-end databases to serve up popular items, such as product descriptions and news stories, also adds to the bottleneck.
The Solution: Distributed Caching
The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. This speeds up accesses and updates while offloading back-end database servers. Also called in-memory data grids, distributed caches, such as ScaleOut StateServer®, use server farms to both scale storage capacity and accelerate access throughput, thereby maintaining fast data access at all times.
The following diagram illustrates how a distributed cache can store fast-changing data to accelerate online performance and offload a back-end database server:
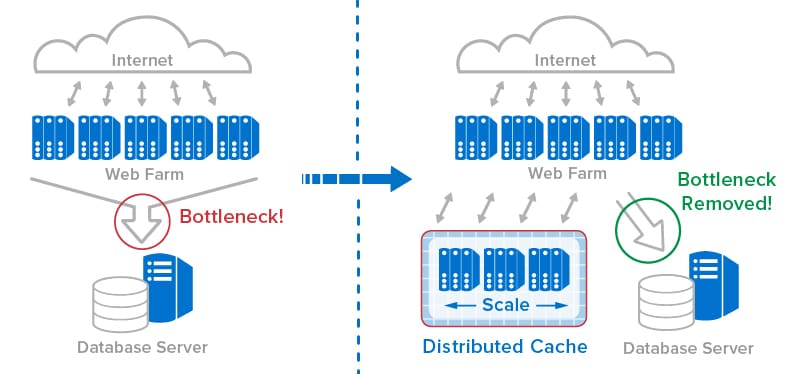
The Technology Behind Distributed Caching
It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches. To be reliable and easy to use, distributed caches need to incorporate technology that provides important attributes, including ease of integration, location transparency, transparent scaling, and high availability with strong consistency. Let’s take a look at some of these capabilities.
To make distributed caches easy to use and keep them fast, they typically employ a “NoSQL” key/value access model and store values as serialized objects. This enables web applications to store, retrieve, and update instances of their application-defined objects (for example, shopping carts) using a simple key, such as a user’s unique identifier. This object-oriented approach allows distributed caches to be viewed as more of an extension of an application’s in-memory data storage than as a separate storage tier.
That said, a web application needs to interact with a distributed cache as a unified whole. It’s just too difficult for the application to keep track of which server within a distributed cache holds a given data object. For this reason, distributed caches handle all the bookkeeping required to keep track of where objects are stored. Applications simply present a key to the distributed cache, and the cache’s client library finds the object, regardless of which server holds it.
It’s also the distributed cache’s responsibility to distribute access requests across its farm of servers and scale throughput as servers are added. Linear scaling keeps access times low as the workload increases. Distributed caches typically use partitioning techniques to accomplish this. ScaleOut StateServer further integrates the cache’s partitioning with its client libraries so that scaling is both transparent to applications and automatic. When a server is added, the cache quietly rebalances the workload across all caching servers and makes the client libraries aware of the changes.
To enable their use in mission-critical applications, distributed caches need to be highly available, that is, to ensure that both stored data and access to the distributed cache can survive the failure of one of the servers. To accomplish this, distributed caches typically store each object on two (or more) servers. If a server fails, the cache detects this, removes the server from the farm, and then restores the redundancy of data storage in case another failure occurs.
When there are multiple copies of an object stored on different servers, it’s important to keep them consistent. Otherwise, stale data due to a missed update could inadvertently be returned to an application after a server fails. Unlike some distributed caches which use a simpler, “eventual” consistency model prone to this problem, ScaleOut StateServer uses a patented, quorum-based technique which ensures that all stored data is fully consistent.
There’s More: Parallel Query and Computing
Because a distributed cache stores memory-based objects on a farm of servers, it can harness the CPU power of the server farm to analyze stored data much faster than would be possible on a single server. For example, instead of just accessing individual objects using keys, it can query the servers in parallel to find all objects with specified properties. With ScaleOut StateServer, applications can use standard query mechanisms, such as Microsoft LINQ, to create parallel queries executed by the distributed cache.
Although they are powerful, parallel queries can overload both a requesting client and the network by returning a large number of query results. In many cases, it makes more sense to let the distributed cache perform the client’s work within the cache itself. ScaleOut StateServer provides an API called Parallel Method Invocation (and also a variant of .NET’s Parallel.ForEach called Distributed ForEach) which lets a client application ship code to the cache that processes the results of a parallel query and then returns merged results back to the client. Moving code to where the data lives accelerates processing while minimizing network usage.
Distributed Caches Can Help Now
Online web sites and services are now more vital than ever to keeping our daily activities moving forward. Since almost all large web sites use server farms to handle growing workloads, it’s no surprise that server farms can also offer a powerful and cost-effective hardware platform for hosting a site’s fast-changing data. Distributed caches harness the power of server farms to handle this important task and remove database bottlenecks. Also, with integrated parallel query and computing, distributed caches can now do much more to offload a site’s workload. This might be a good time to take a fresh look at the power of distributed caching.

Dr. William L. Bain is the founder and CEO of ScaleOut Software, which has been developing software products since 2003 designed to enhance operational intelligence within live systems using scalable, in-memory computing technology. Bill earned a Ph.D. in electrical engineering from Rice University. With over a 40-year career focused on parallel computing, he has contributed to advancements at Bell Labs Research, Intel, and Microsoft, and holds several patents in computer architecture and distributed computing.