
by Olivier Tritschler, Senior Software Engineer
Because of their ability to provide highly elastic computing resources, public clouds have become a highly attractive platform for hosting distributed caches, such as ScaleOut StateServer®. To complement its current offerings on Amazon AWS and Microsoft Azure, ScaleOut Software has just announced support for the Google Cloud Platform. Let’s take a look at some of the benefits of hosting distributed caches in the cloud and understand how we have worked to make both deployment and management as simple as possible.
Distributed Caching in the Cloud
Distributed caches, like ScaleOut StateServer, enhance a wide range of applications by offering shared, in-memory storage for fast-changing state information, such as shopping carts, financial transactions, geolocation data, etc. This data needs to be quickly updated and shared across all application servers, ensuring consistent tracking of user state regardless of the server handling a request. Distributed caches also offer a powerful computing platform for analyzing live data and generating immediate feedback or operational intelligence for applications.
Built using a cluster of virtual or physical servers, distributed caches automatically scale access throughput and analytics to handle large workloads. With their tightly integrated client-side caching, these caches typically provide faster access to fast-changing data than backing stores, such as blob stores and database servers. In addition, they incorporate redundant data storage and recovery techniques to provide built-in high availability and ensure uninterrupted access if a server fails.
To meet the needs of elastic applications, distributed caches must themselves be elastic. They are designed to transparently scale upwards or downwards by adding or removing servers as the workload varies. This is where the power of the cloud becomes clear.
Because cloud infrastructures provide inherent elasticity, they can benefit both applications and distributed caches. As more computing resources are needed to handle a growing workload, clouds can deploy additional virtual servers (also called cloud “instances”). Once a period of high demand subsides, resources can be dialed back to minimize cost without compromising quality of service. The flexibility of on-demand servers also avoids costly capital investments and reduces management costs.
Deploying ScaleOut’s Distributed Cache in the Google Cloud
A key challenge in using a distributed cache as part of a cloud-hosted application is to make it easy to deploy, manage, and access by the application. Distributed caches are typically deployed in the cloud as a cluster of virtual servers that scales as the workload demands. To keep it simple, a cloud-hosted application should just view a distributed cache as an abstract entity and not have to keep track of individual caching servers or which data they hold. The application does not want to be concerned with connecting N application instances to M caching servers, especially when N and M (as well as cloud IP addresses) vary over time. In particular, an application should not have to discover and track the IP addresses for the caching servers.
Even though a distributed cache comprises several servers, the simplest way to deploy and manage it in the cloud is to identify the cache as a single, coherent service. ScaleOut StateServer takes this approach by identifying a cloud-hosted distributed cache with a single “store” name combined with access credentials. This name becomes the basis for both managing the deployed servers and connecting applications to the cache. It lets applications connect to the caching cluster without needing to be aware of the IP addresses for the cluster’s virtual servers.
The following diagram shows a ScaleOut StateServer distributed cache deployed in Google Cloud. It shows both cloud-hosted and on-premises applications connected to the cache, as well as ScaleOut’s management console, which lets users deploy and manage the cache. Note that while the distributed cache and applications all contain multiple servers, applications and users can access the cache just by using its store name.
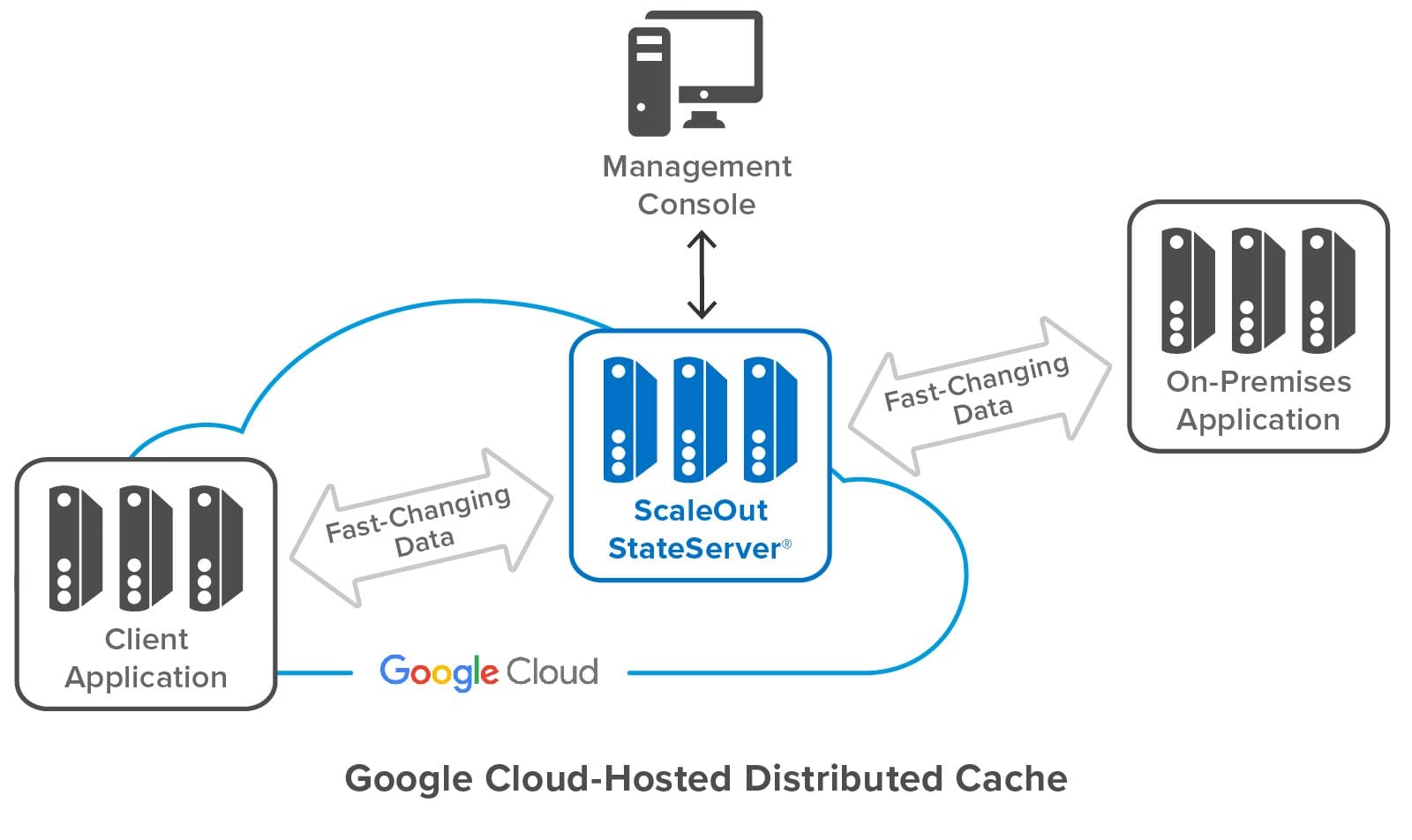
Building on the features developed for the integration of Amazon AWS and Microsoft Azure, the ScaleOut Management Console now lets users deploy and manage a cache in Google Cloud by just specifying a store name and initial number of servers, as well as other optional parameters. The console does the rest, interacting with Google Cloud to start up the distributed cache and configure its servers. To enable the servers to form a cluster, the console records metadata for all servers and identifies them as having the same store name.
Here’s a screenshot of the console wizard used for deploying ScaleOut StateServer in Google Cloud:
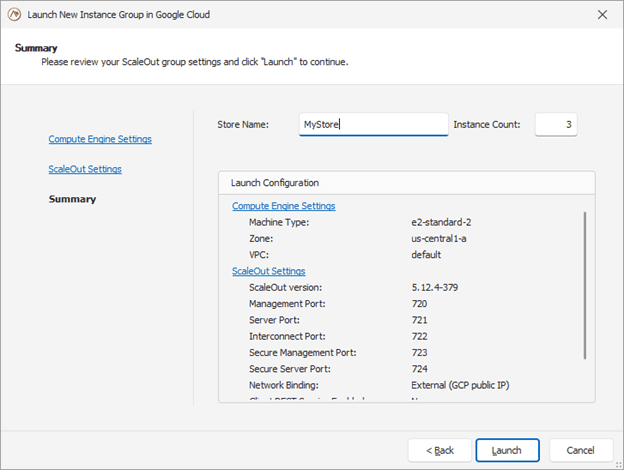
The management console provides centralized, on-premises management for initial deployment, status tracking, and adding or removing servers. It uses Google’s managed instance groups to host servers, and automated scripts use server metadata to guarantee that new servers automatically connect with an existing store. The managed instance groups used by ScaleOut also support defining auto-scaling options based on CPU/Memory usage metrics.
Instead of using the management console, users can also deploy ScaleOut StateServer to Google Cloud directly with Google’s Deployment Manager using optional templates and configuration files.
Simplifying Connectivity for Applications
On-premises applications typically connect each client instance to a distributed cache using a fixed list of IP addresses for the caching servers. This process works well on premises because the cache’s IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of a caching server.
To avoid this problem, ScaleOut StateServer lets client applications specify a store name and credentials to access a cloud-hosted distributed cache. ScaleOut’s client libraries internally use this store name to discover the IP addresses of caching servers from metadata stored in each server.
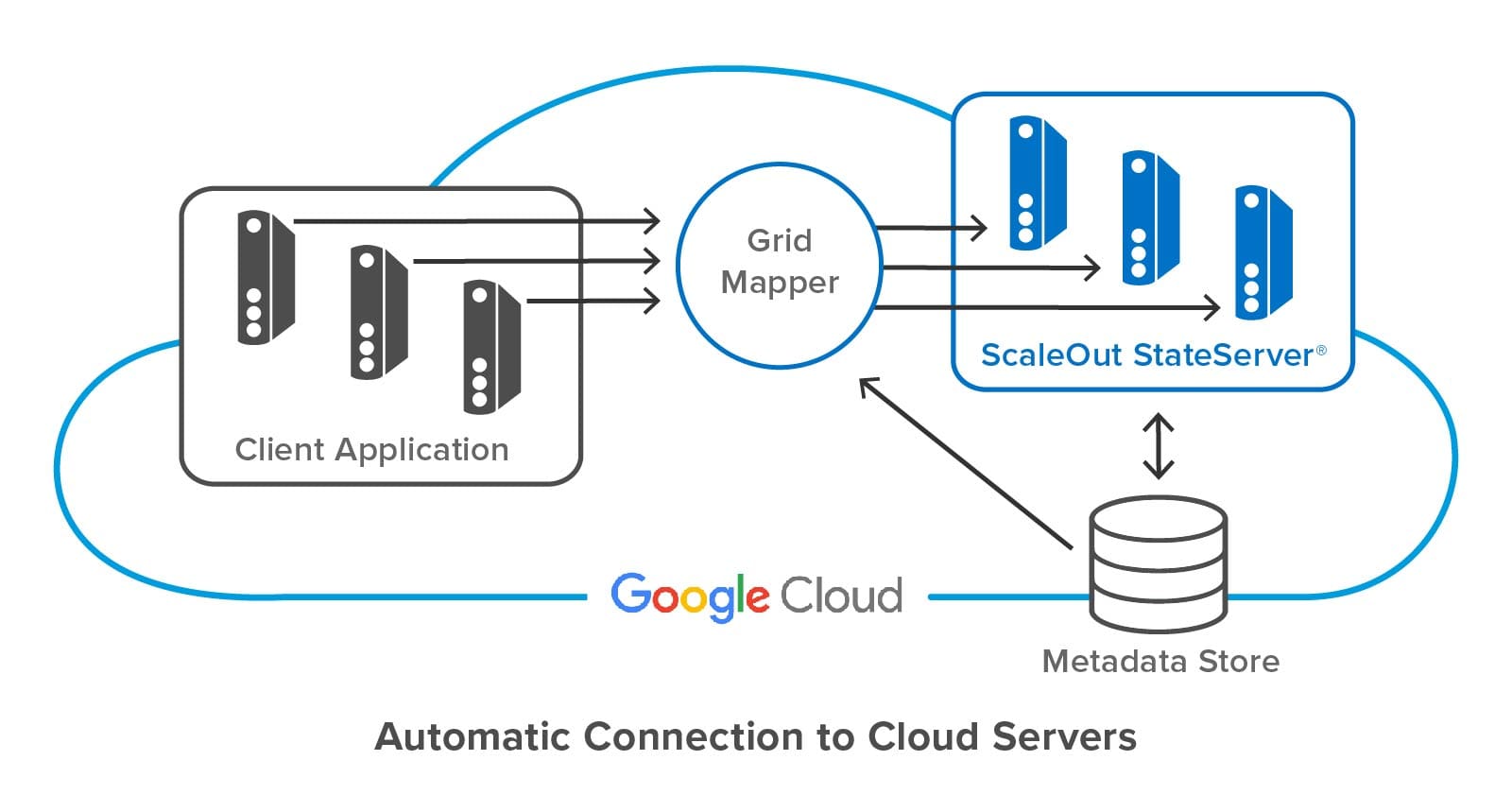
The following diagram shows a client application connecting to a ScaleOut StateServer distributed cache hosted in Google Cloud. ScaleOut’s client libraries make use of an internal software component called a “grid mapper” which acts as a bootstrap mechanism to find all servers belonging to a specified cache using its store name. The grid mapper accesses the metadata for the associated caching servers and returns their IP addresses back to the client library. The grid mapper handles any potential changes in IP addresses, such as servers being added or removed for scaling purposes.
Summing up
Because they provide elastic computing resources and high performance, public clouds, such as Google Cloud, offer an excellent platform for hosting distributed caches. However, the ephemeral nature of their virtual servers introduces challenges for both deploying the cluster and connecting applications. Keeping deployment and management as simple as possible is essential to controlling operational costs. ScaleOut StateServer makes use of centralized management, server metadata, and automatic client connections to address these challenges. It ensures that applications derive the full benefits of the cloud’s elastic resources with maximum ease of use and minimum cost.