By Dr. William L. Bain
Attending technical conferences creates the opportunity to step away from focusing on day-to-day concerns and reflect more deeply about the key principles that guide our work. Having just concluded participation in another In-Memory Computing Summit, it has become even more clear to me that the key to mainstream adoption of in-memory computing software platforms is architecture — the root of a platform’s value to applications. This notion has been reinforced through four decades of work in computer architecture and software after it was first driven home to me by a luminary in computer architecture at Intel Corporation, the late George Cox.
The importance of architecture remains as true as ever, although it is often overlooked by application developers, who have deadlines to hit, and by platform developers, who have features and APIs to ship. These priorities tend to push the architecture to the back burner. But careful analysis of application requirements often results in important insights that influence the platform’s architecture and lead to new value for all applications. It is our job as software platform architects to look for these opportunities and hopefully integrate them into our architectures in a skillful manner.
The digital twin model for stateful stream-processing is a case in point. In a previous blog, we explored how this model for building stream-processing applications naturally shifts the application’s focus from the event stream to the data sources that are sending events. By correlating incoming events and co-locating all relevant state information for each data source, an in-memory computing platform can ensure that a stream-processing application has the context it needs to analyze the data source’s dynamic state and generate effective, real-time feedback.
For example, if an application is analyzing telemetry from the components of a windmill, it can zoom in on the telemetry for each component and combine this with relevant contextual data, such as the component’s make, model, and service history, to enhance its ability to predict impending failures. The following diagram illustrates how the digital twin model correlates telemetry from three components of a hypothetical windmill (blades, generator, and control panel) and delivers it to associated objects within an in-memory data grid (IMDG), where event handlers analyze the telemetry and generate feedback and alerts:
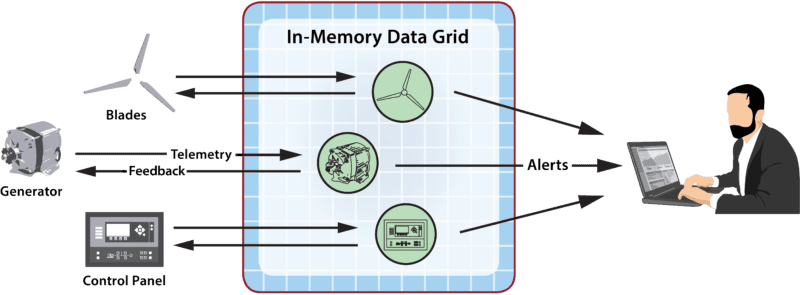
The power of the digital twin model is that this software architecture gives applications new capabilities, simplifies development, and boosts performance. While the model alone does not provide specific APIs for predictive analytics or machine learning, its architecture provides an organizational structure for hosting application-specific algorithms so that they have immediate access to the context they need for deep introspection.
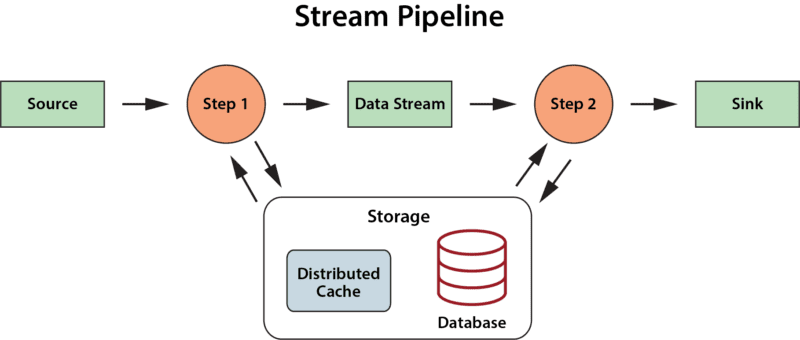
Compare the digital twin model to standard, pipelined models for stream-processing, such as Apache Beam, which require the application to orchestrate the correlation of events by data source and manage each data source’s state information in unstructured attached storage – at the cost of both complexity and increased network overhead. (See the diagram below.) When implemented on an IMDG with integrated in-memory computing, the digital twin model provides a higher-level abstraction that both simplifies application design and avoids network accesses to a remote store. As a result, it makes sense to factor its functionality out of application code and migrate it into the platform.
One indicator of a useful software architecture is that it provides unexpected benefits. This is the case with digital twins. Beyond just using them to model physical data sources, they can be organized in a hierarchy to implement subsystems operating at successively higher levels of abstraction within a real-time application. Alerts from lower-level digital twins can be delivered as telemetry to higher level twins in an acyclic, directed graph that partitions functionality in a hierarchical manner and enables strategic algorithms to be cleanly encapsulated.
In our above example of a windmill that generates telemetry from three physical components, the blades and generator work together to generate power managed by the control panel. Taking advantage of a hierarchical organization as shown below, the digital twins for the blades and generator feed telemetry to a higher-level digital twin model called the Blade System that manages the rotating components within the tower and their common concerns, such as avoiding over-speeds, while not dealing with the detailed issues of managing these two components. Likewise, the digital twin for the blade system and the control panel feed telemetry to a yet higher level digital twin model which coordinates the overall windmill’s operation and generates alerts as necessary.
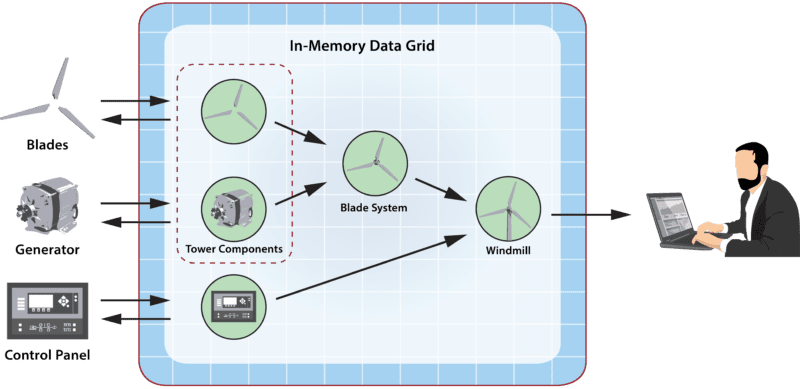
By partitioning the application in a hierarchical manner, the code can be modularized and thereby simplified with a clean separation of concerns and well-defined interfaces for testing. In many ways, the digital twin model is just an application of the principle of encapsulation from object-oriented programming to the data sources and higher-level controllers within a real-time, stream-processing system. In fact, the software architecture of digital twins is so simple that it might be overlooked or trivialized. However, this model significantly simplifies application development and enables the platform to maximize stream-processing performance. The benefits it provides for applications, especially when they are hosted on an in-memory computing platform with first-class support for digital twins, should not be underestimated.

Dr. William L. Bain is the founder and CEO of ScaleOut Software, which has been developing software products since 2003 designed to enhance operational intelligence within live systems using scalable, in-memory computing technology. Bill earned a Ph.D. in electrical engineering from Rice University. With over a 40-year career focused on parallel computing, he has contributed to advancements at Bell Labs Research, Intel, and Microsoft, and holds several patents in computer architecture and distributed computing.