We have spent a great deal of time at ScaleOut Software re-architecting our in-memory data grid (IMDG)’s code base to make best use of many cores and large memory. For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Also, load-balancing after membership changes must be both multi-threaded and pipelined to drive the network at maximum bandwidth.
Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers. In addition to looking at performance differences, we also want to compare ScaleOut StateServer (SOSS) to AppFabric on qualitative measures, such as features, ease of installation, and management.
Testing Scale-Up Performance
Well, performance comparisons aren’t so easy since the AppFabric license agreement states: “You may not disclose the results of any benchmark tests of the software to any third party without Microsoft’s prior written approval.” So our comments will be confined to what testing we felt was valuable and how well SOSS performed.
In a recent customer engagement, the application needed to load 10M objects into each server of the IMDG’s cluster to make full use of high-end servers with 60GB memory capacity. Measuring object creation and access rates on a single server is a good test of the IMDG’s memory management and multithreading, and this is an area in which we have made several performance optimizations. Using a workload of random object sizes varying from 200B to 2KB, SOSS was able to load 2 million objects in 59.2 seconds and then sustain 18K read/update pairs per second to random objects. That’s actually quite fast. (We invite you to test AppFabric’s performance; contact us if you need a test application.)
We also looked at load-balancing and recovery times for this workload of 2M objects when adding a server to a 2-server cluster, removing the third server, and also just killing the third server. This measures how well the IMDG’s servers use multithreading to maximize network bandwidth during load-balancing, and it also evaluates failure detection and recovery algorithms. These are areas in which we have invested heavily to take advantage of 10 Gbps (and faster) networks and to handle intermittent network delays inherent in virtual server infrastructures. While handling an access load of 6K read/update pairs per second, SOSS was measured to complete load-balancing in less than 35 seconds for joins and leaves and also to complete recovery and restore full throughput in this amount of time after a server failure.
Unwanted Client Exceptions from AppFabric
We were surprised to discover that AppFabric throws exceptions to the client application during load-balancing and recovery and due to security issues, as described in other blog posts. During load-balancing, the client gets the following exception when accessing the cache:
ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later. (One or more specified cache servers are unavailable, which could be caused by busy network or servers. …)
You’ll also see a “Please retry later” exception (forever!) if the client runs with insufficient security authorization; we had to run the client as administrator to avoid problems without a much deeper investigation. The client also throws these exceptions during “graceful” host shutdowns and during recovery.
To keep application development as straightforward as possible, SOSS handles all exceptions that occur during membership changes and load-balancing, automatically retrying requests within the server as necessary. This avoids exposing the application to the details of the IMDG’s internal operations unless the IMDG is completely unreachable.
A Few Words on Design Philosophy: Keep It Simple
Our experience with customers consistently reinforces the need to keep middleware software as easy to install and use as possible, especially given that it is deployed as distributed software running on a cluster of servers. This philosophy manifests itself in all areas, including installation, application development, and cluster management. We believe that installing our software should be as straightforward as we can make it, requiring minimal knowledge of the host operating system and the fewest possible explicit configuration settings.
AppFabric caching does not share this design approach and requires the configuration of numerous components, including security policies, SQL Server or a network file share with the appropriate permissions, “lead” hosts, etc. Also, a long list of PowerShell commands for managing the cache must be learned and correctly used. Running AppFabric caching in production typically requires the use of a domain and is deeply tied into the Windows Server infrastructure. As expected, AppFabric requires the comprehensive knowledge of a Windows system administrator to install and manage.
In our testing, the net result was about a half-day investment in time on our part (and some frustration) getting AppFabric up and running. After spending an hour trying to join multiple cluster hosts in a Windows workgroup, we switched to using a domain controller to make this work; it just wasn’t worth the time to sort out the incorrect configuration settings. Head scratching was required in several other areas before our AppFabric cluster showed signs of life.
GUI Based Management Is Crucial for Distributed Software
A major source of frustration with AppFabric is its use of PowerShell commands to manage the cache cluster. It’s easy to forget that distributed software is running on multiple servers which need to be orchestrated as a group, and that’s hard to do with a sequence of shell commands because you can’t track the state of the cluster at a glance. It’s much easier to manage a cluster with a graphical user interface (GUI) which shows the status of all hosts and alerts you to dynamic situations, such as high usage, load-balancing, or network outages.
To take full advantage of the GUI approach, SOSS uses a Windows-based management console with intuitive controls that make management of the IMDG simple and easy to learn. The console also adds advanced visualization features, such as integrated performance charts and tabular usage charts, a “heat” map showing the availability and dynamic state of all regions within the distributed store, and an object browser that lets you see stored objects and examine both their metadata and contents.
The following screenshots illustrate SOSS’s performance charting and heat map. Note that the status of the IMDG and all cluster hosts is instantly visible in the tree list at the left:
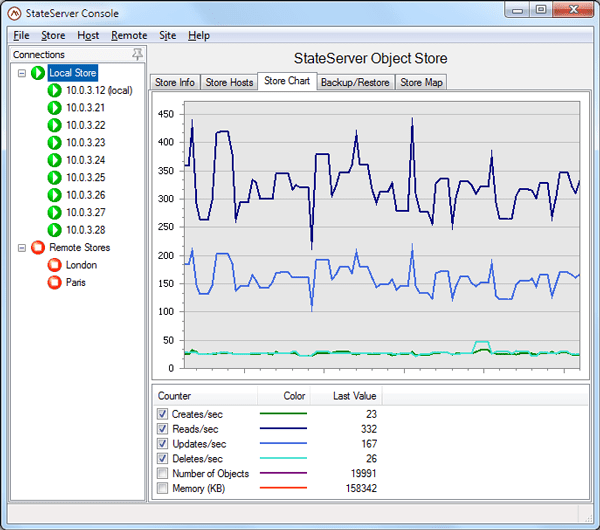
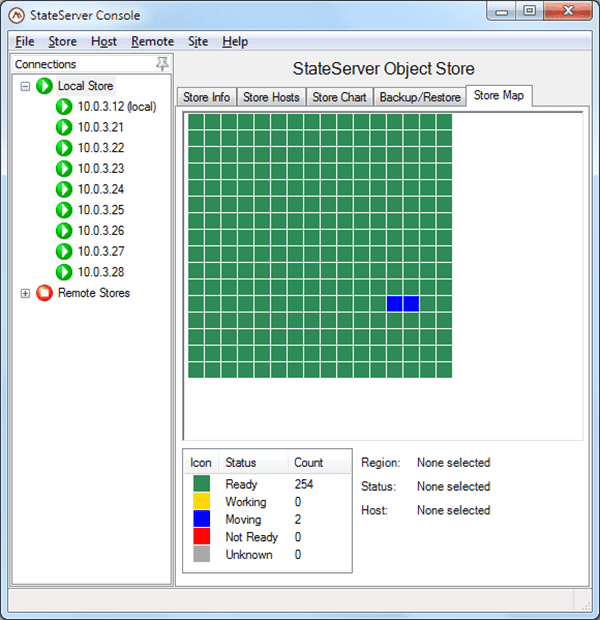
Because the GUI management console receives periodic updates from all cluster hosts, it stays tightly integrated with the cluster and dynamically updates the latest status. In contrast, the use of shell commands just gives you a snapshot of the state of the cluster at one instant in time. We also have observed that these results quickly can become out of sync with what client applications are actually experiencing. For example, a shell command can report that the cluster is in an unknown state when in fact the client is successfully completing access requests. (In AppFabric, be prepared to wait for several seconds for management commands to time out when a cluster host goes into an unknown state.)
Use Fully Peer-to-Peer Design for Simplicity and High Availability
AppFabric uses a single store, either a file share or SQL Server, to hold the cluster’s configuration, which adds complexity to installation and creates a single point of failure. Although SQL Server can be clustered, this adds even more cost than just using a single server. To avoid these problems, SOSS automatically replicates its configuration files on every cluster host to maximize availability with a fully peer-to-peer implementation. This approach also keeps the user from having to deal with managing a configuration store.
The peer-to-peer issue arises again in AppFabric’s requiring a majority of lead hosts (presumably) to reconfigure the cluster after a membership change. Because some hosts are lead hosts and others are not, an AppFabric caching cluster will go down even when hosts are healthy. Moreover, the administrator has to understand and ensure that a majority hosts quorum of lead hosts exists, and the number of lead hosts varies with cluster size. For example, a small cluster of up to 20 hosts might use 3 lead hosts, requiring two hosts to form a quorum. If 2 of the 3 lead hosts go down, the cluster will go down even if there are 18 healthy hosts.
With ScaleOut, you don’t need to know what the word “quorum” means. SOSS sidesteps these issues by using a fully peer-to-peer membership so that all hosts can participate in constructing the cluster membership. (SOSS makes use of a ScaleOut Software patent which eliminates the need for a majority hosts quorum by building a logical quorum on a uniform set of servers.) This means that SOSS can avoid the use of lead hosts and maintains service as long as any host survives. System administrators view all cluster hosts as peers and do not have to be aware of SOSS’s internal mechanisms for implementing the cluster membership.
Distributed Cache or In-Memory Data Grid?
It’s actually not clear to us whether AppFabric’s design philosophy regarding high availability is more closely aligned with “best effort” distributed caches like memcached or with mission-critical in-memory data grids like SOSS and others. Data replication is turned off by default and is explicitly set on a namespace-by-namespace basis using management commands. (High availability apparently is not available on Windows Server 2008R2 Standard Edition and requires Enterprise Edition, which can cost about $2,800 more per server, or you must upgrade to Windows Server 2012.) Also, since data is hosted in managed code, access delays due to garbage collection (as well as the exceptions noted above) are to be expected. (Microsoft recommends not storing more than 16GB in a cache host to avoid GC pauses.) Lastly, AppFabric’s client cache is not kept coherent with the distributed cache, and so the client cache cannot be used for transactional data.
In contrast, SOSS automatically replicates all stored objects on multiple hosts to maintain high availability at all times. Likewise, it uses an unmanaged heap for stored data to keep access times as predictable as possible and avoid GC pauses. It also keeps all client caches coherent with the IMDG so that multi-threaded code running on the cluster can coordinate access to transactional data using the well understood sequential consistency model.
In Summary: Design for Ease of Use and High Performance
It was tempting to write this blog post as a feature comparison between AppFabric and SOSS. It’s clear that, as a full in-memory data grid, SOSS — unlike AppFabric — incorporates many features that go well beyond distributed caching. For example, SOSS lets applications query stored data by property using Microsoft’s own LINQ, and ScaleOut Analytics Server (SOAS) can perform data-parallel analysis of queried objects using application code that SOAS automatically deploys on the cluster. ScaleOut hServer takes analytics a step further by hosting full Hadoop MapReduce on the IMDG.
That said, since AppFabric is targeted at distributed caching, we felt that AppFabric users likely are more focused on issues regarding deployment, performance, and availability. Beyond just evaluating how well products like AppFabric and SOSS extract performance from scale-up, it’s also important to examine how they stack up in their overall role of providing scalable, highly available in-memory storage.
When looking at other design approaches, we feel that ScaleOut’s philosophy of easy-to-use, fully peer-to-peer design with GUI-based management provides important dividends by simplifying deployment and maximizing visibility, while driving high performance and availability. Not surprisingly, all of this lowers the total cost of ownership, which — as we have seen — even for “free” software is never zero.