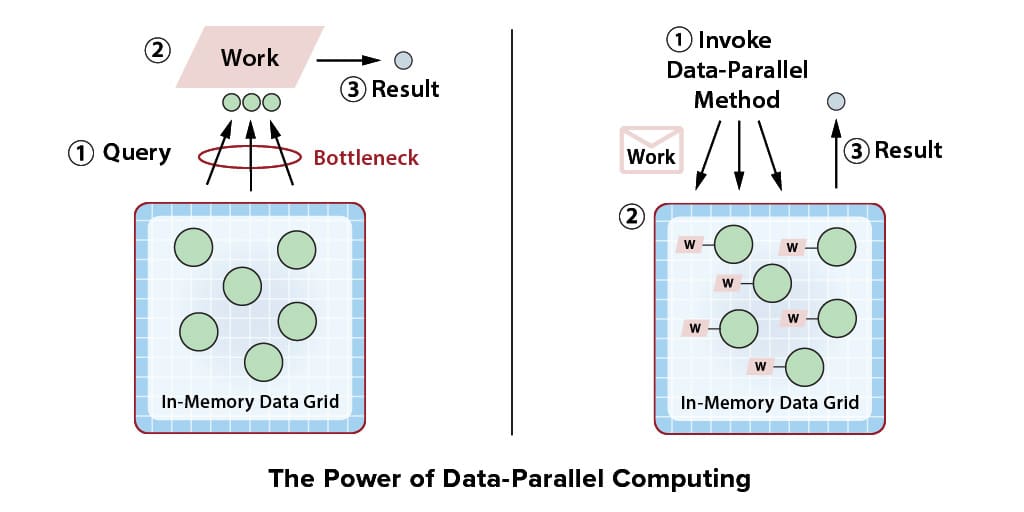
Although invoking a parallel query on an in-memory data grid (IMDG) is fast and provides scalable throughput, it can easily create a network bottleneck and then overload the client with work. A query that matches a large set of objects can send huge amounts of data back to the invoking client, and this can saturate the network. Once the client receives the query results, it must examine all of the objects to perform its desired work. Although query lookup within an IMDG’s cluster of servers takes advantage of scalable computing power, the network and the client have fixed resources which create significantly delays that extend the overall time required to complete all of the work.
Instead of using parallel query, consider running a data-parallel method within the IMDG to both query and perform the client’s work. ScaleOut StateServer® Pro offers an API for this purpose called “parallel method invocation” (and a variation of parallel foreach for .NET called “distributed foreach”). It lets a client application specify both a query expression and a Java or C# method to perform on the objects selected by the query, as well as a second method to combine the results and return a final, merged result back to the client. ScaleOut’s client libraries automatically ship the code and query spec to the IMDG, which runs everything in parallel on its cluster of servers before shipping back the final result. This ensures that all steps are performed in parallel for fast completion and scalable throughput. In addition, it eliminates network bottlenecks and reduces client CPU overhead.
So the next time you need to query objects held in an IMDG, consider using data-parallel computing instead. It’s fast and easier to use than you might think. Learn more about data-parallel computing here.

Dr. William L. Bain is the founder and CEO of ScaleOut Software, which has been developing software products since 2003 designed to enhance operational intelligence within live systems using scalable, in-memory computing technology. Bill earned a Ph.D. in electrical engineering from Rice University. With over a 40-year career focused on parallel computing, he has contributed to advancements at Bell Labs Research, Intel, and Microsoft, and holds several patents in computer architecture and distributed computing.