
The Need for New Cache Technology
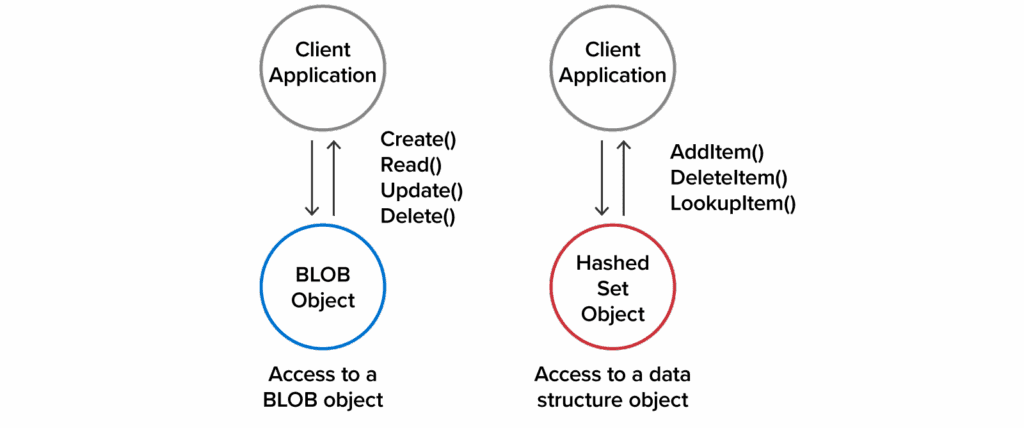
For the last two decades, distributed caches (also known as in-memory data grids) have powered the scaling of server-based applications, like e-commerce sites and customer portals. Their ability to store fast-changing data in memory and distribute it seamlessly across a cluster of physical or virtual servers enables them to keep response times fast even as workloads grow to handle ever-increasing demand. Because they provide a straightforward view of data as a key-value store hosting uninterpreted data (called BLOBs), applications can easily integrate them into their data access mechanisms.
The simplicity of the key-value access model can create additional overhead when storing large objects (typically, a megabyte or more per object). Applications may need to retrieve large amounts of data to access or update an object with relatively small changes. The addition of data structures to distributed caches addresses this concern. Some distributed caches implement a limited set of data structures, like hashed sets or sorted sets, which they store in cached objects. They provide APIs that client applications can invoke to perform operations on these data structures.
With data structure APIs, applications can send and retrieve much smaller amounts of data to manage the associated objects. For example, they can add an item to a large, hashed set by just sending an item to the cache instead of retrieving the entire set, adding the item to the set, and sending the updated hash set back to the cache. This greatly reduces network overhead between client applications and the distributed cache.
Here’s a comparison between accessing objects as BLOBs and using data structure APIs:
Although today’s data structure stores are highly useful, their limited set of built-in data structures can’t handle all use cases, it can be difficult to add new data structures. They may have to be written in the same language as the distributed cache (for example, C), and they may have to be linked to and run within the server. This process can be complex, and errors in new data structure code might bring down the distributed cache.
What’s needed is a better set of tools for adding data structures to a distributed cache. These tools should let application developers use modern, strongly typed languages, dynamically add new data structures to the cache, automatically take advantage of cluster scaling, and protect the cache from errors. This would enable developers to easily build highly customized data structures that meet their specific needs.
Introducing ScaleOut Active Caching
Now available in ScaleOut Product Suite’s version 6, ScaleOut Active Caching™ addresses these challenges with a set of tools for deploying application-defined data structures to the ScaleOut StateServer distributed cache. This toolset calls data structures and the code that manages them modules, with one module for each type of data structure describing objects in a single namespace within the cache. Developers can use either Java or C# to implement modules and take advantage of type checking provided by these languages. Using a new management UI, they can deploy modules to an operational distributed cache whenever needed.
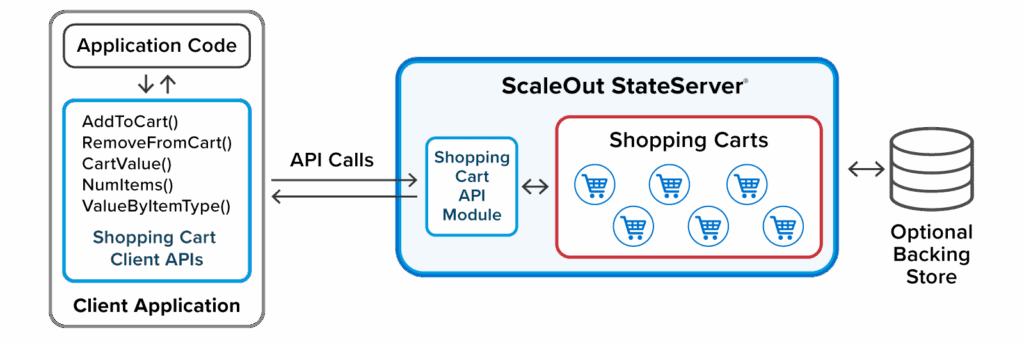
ScaleOut Active Caching provides two types of modules for embedding application code in the distributed cache: API modules and message modules. API modules define new data structures and APIs that are invoked by client applications. They let developers build and deploy data structures that customize how cached objects are managed according to specific application needs. These data structures offload application code to the distributed cache and accelerate performance. They also lower network overhead by reducing the amount of data that needs to be exchanged between clients and the cache. Because they are easy to implement and deploy, they can address highly specific application requirements.
For example, an e-commerce company can build a shopping cart data structure that fits its unique needs. The APIs can be purpose-built to extract and update exactly the information that the business requires:
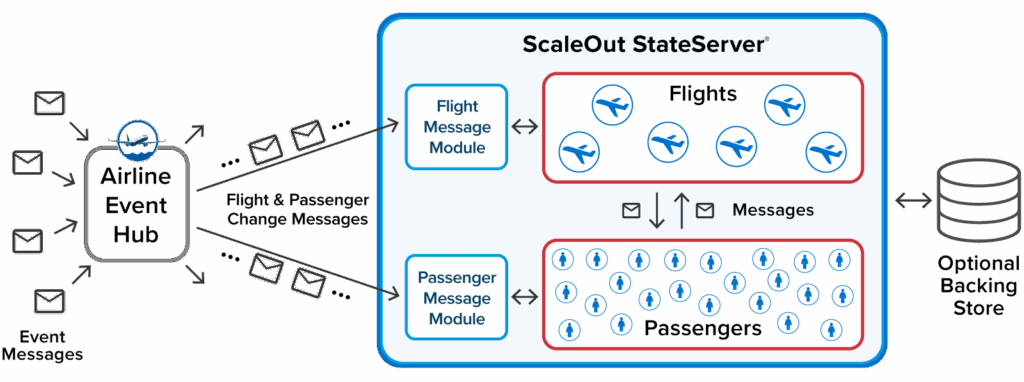
Using message modules, developers can deploy strongly typed code to the distributed cache to process incoming messages. Message modules connect to messaging hubs like Kafka or a built-in REST server and direct messages to specific objects in the distributed cache. These modules are designed to integrate into an event-driven architecture and accelerate message processing using the cache’s memory-based data. When running in the cloud, they can help eliminate the need for serverless functions and the problems they can create (locking, retries, and maintainability).
For example, an airline can use message modules to implement event-processing functions for managing flight changes and passenger re-bookings. The distributed cache can automatically stage “hot” objects in the cache from a backing store and persist changes as needed:
Scaling Performance and Maintaining Reliability
When the management UI deploys a module, an instance of the module’s service process (a Java JVM or .NET runtime) runs on every server in the distributed cache. Each module instance connects to its local cache service process to receive incoming requests (API invocations or messages) and deliver responses, as illustrated here:
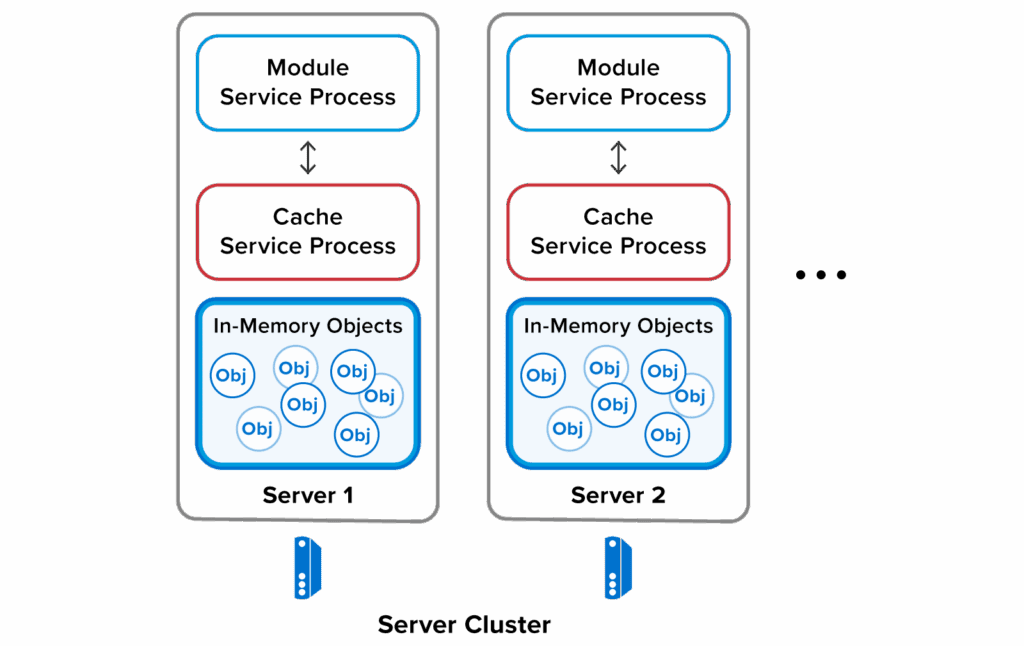
Incoming requests are handled by the server on which the primary copy of the target object is stored. This architecture enables multiple module instances to process requests in parallel by automatically distributing the processing workload across all cache servers. It seamlessly scales throughput as cache servers join the cluster.
Since module instances run in separate processes, they cannot destabilize the cache service processes. This allows users to deploy modules to a live cache without concern that they might interrupt access to data.
Summing Up
For distributed caching to reach its full potential in scaling application performance, it must provide the most efficient possible access to in-memory data, and it must enable applications to take full advantage of cluster scaling. While data structure caches took a big step in this direction, they still required applications to adapt to the limited set of data structures they offer.
ScaleOut Active Caching creates the next generation in the evolution of distributed caching by enabling developers to easily deploy custom data structures and automatically scale their performance. It also supports event-processing to seamlessly integrate into today’s cloud infrastructures and provide a more compelling development approach than serverless functions.
To learn more about active caching and other exciting new features in version 6, like data visualization, check out the ScaleOut Active Caching web page here.