The recently announced security vulnerability (CVE-2025-49844) for a widely used data structure store illustrates the risk of running application code within the core service processes of a distributed cache. While this vulnerability principally affects deployments that are directly exposed to the Internet and also have authentication disabled, it provides the opportunity to examine the techniques, benefits, and risks of hosting application code in a distributed cache.
As described in an earlier post, distributed caches traditionally store opaque, binary objects called BLOBs using a simple key-value access model. They distribute memory-based object storage across multiple servers using a cluster of cache service processes:
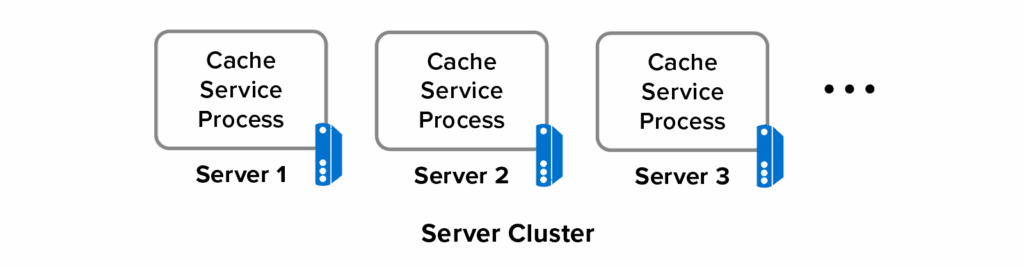
As objects grow large relative to available network bandwidth, network overhead starts to bog down access performance. For example, at its peak, a gigabit network can only transfer about 100 megabytes per second; thousands of cache reads and updates per second to a 1 megabyte or larger object can easily saturate the network. (That also shows why using a single “hot” object is a bad idea. It’s better to spread the workload over many objects distributed across multiple servers.)
As explained in the earlier post, data structure stores have both simplified client code and ameliorated performance bottlenecks by providing APIs that treat cached objects as data types accessed using fine-grained operations instead of treating them as BLOBs that must be moved back and forth. For example, if a cached object holds a sorted set, APIs can just add, remove, and read sorted items instead of retrieving the entire set.
However, a fixed number of built-in data structures can only address the most general use cases. Applications need a way to handle specific needs, like implementing a shopping cart for an e-commerce site. One way to do this is to allow users to run scripts within cache servers to perform application-specific actions. This technique provides a flexible way to customize cache accesses, and it has the added benefit of extremely fast access time to cached data:
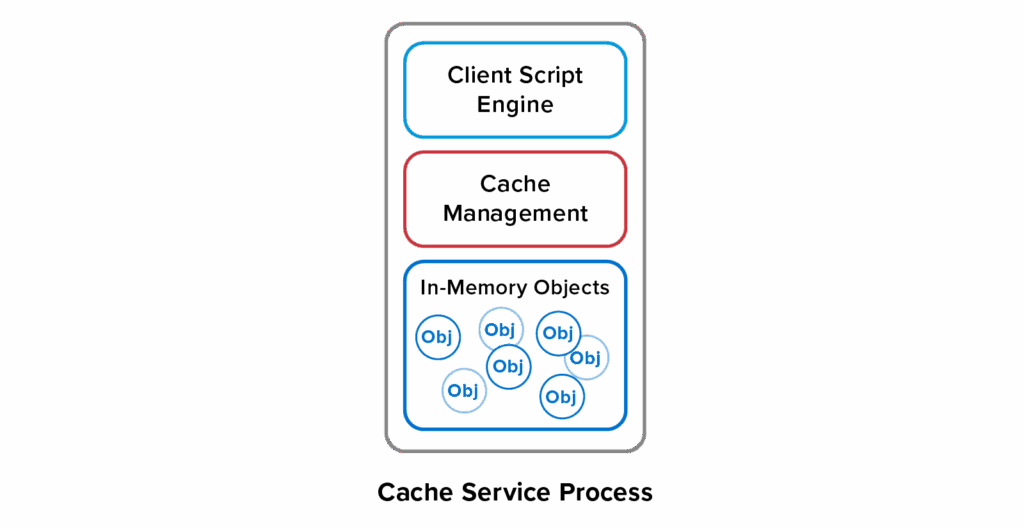 Embedding a client script engine is the software architecture that opened the door to the CVE-2025-49844 security vulnerability. Malicious application code can run amok in the cache service process. There are other tradeoffs, as well. Application code must be implemented in a scripting language like Lua instead of more powerful, strongly typed languages like Java and C#. This often means that application code must be developed and maintained in multiple languages.
Embedding a client script engine is the software architecture that opened the door to the CVE-2025-49844 security vulnerability. Malicious application code can run amok in the cache service process. There are other tradeoffs, as well. Application code must be implemented in a scripting language like Lua instead of more powerful, strongly typed languages like Java and C#. This often means that application code must be developed and maintained in multiple languages.
At ScaleOut Software, we have recognized the value of deploying application code to the distributed cache and have created an alternative software architecture for this purpose. Our goal was to take full advantage of a data structure store while avoiding the pitfalls of server-side scripting or extension modules that must be bound into the cache service. We wanted to let developers use mainstream languages for building extensions and isolate application code from the cache service itself.
To meet these needs, we recently delivered a new feature set called ScaleOut Active Caching™ with version 6 of the ScaleOut Product Suite™. This feature set lets developers create new data structures in Java or C# for accessing and updating cached objects. Called API modules, these data structures define APIs called by client applications. (ScaleOut Active Caching also provides message modules for processing messages within an event-driven architecture.) Modules are developed using language-specific templates and then deployed to the distributed cache from a management UI. They can be added and removed at any time.
To host Java and C# runtime environments, API and message modules run in separate processes, one per module:
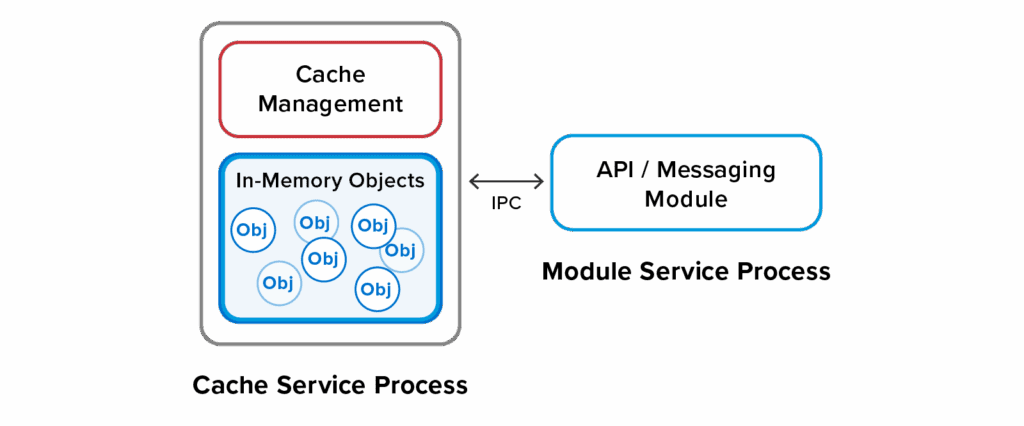
This approach has the advantage of isolating application code from the cache service process. If properly restricted, module processes cannot take over the system. However, since they are application-defined, they are not prevented from other nefarious behaviors, like mining Bitcoin.
One downside to using a separate process for application code is slower access to cached data than running within the cache service; cached objects must be transferred across an IPC connection within the server. However, IPC is many times faster than transferring data across the network to clients. To partially mitigate this issue, API and message modules can take advantage of near-caching within the module itself.
In summary, the notion of treating distributed caches as data structure stores creates fundamental benefits. The challenge has been how to make data structure stores extensible so that they can easily add new, usually application-specific, data structures. Adding extensions within the cache service itself has limitations and creates problems, like security vulnerabilities. However, hosting application-defined data structures in separate processes has several advantages. We believe that this innovation will create substantial benefits for application developers as a next-generation architecture for distributed caching.