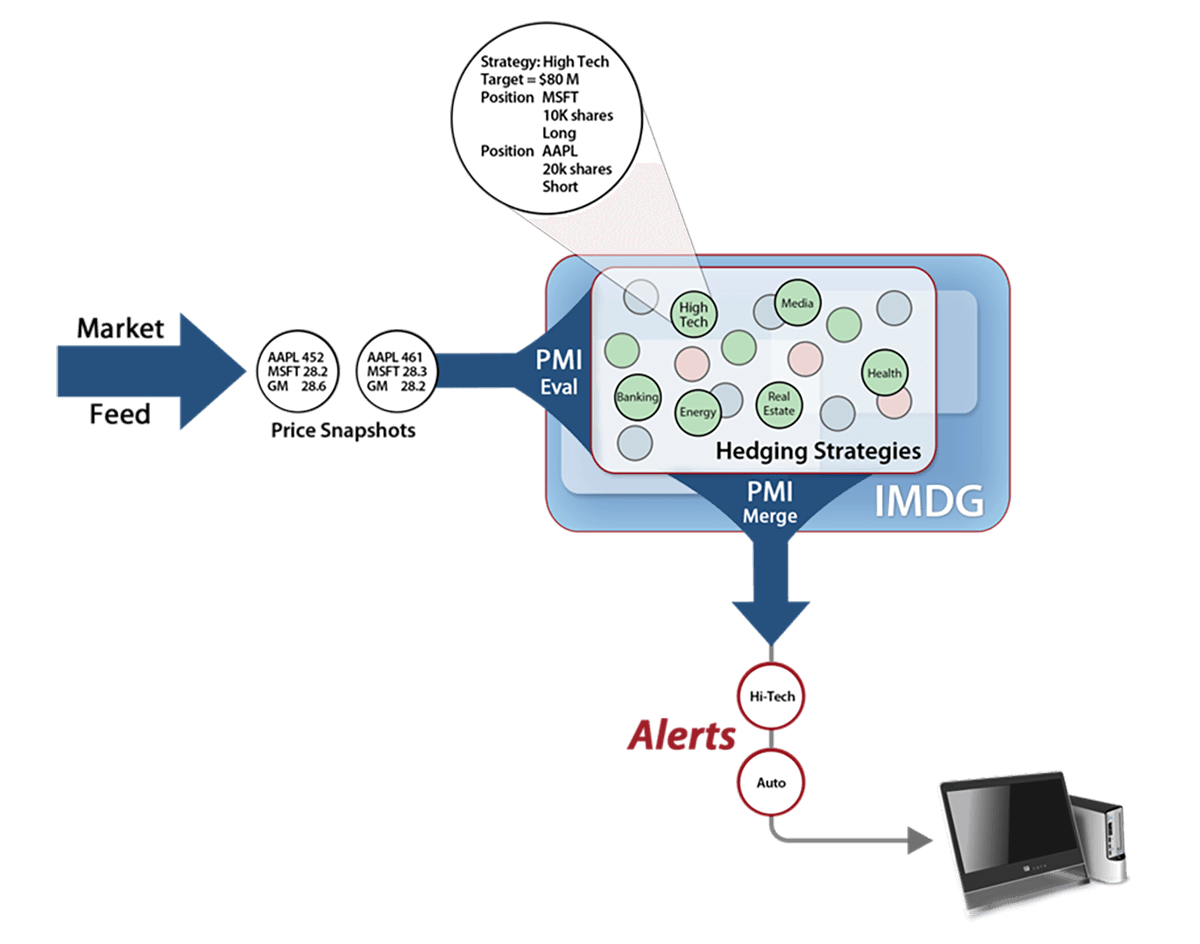
The Challenge
A large hedge fund in New York employs more than a thousand different equity investment strategies that are constructed using a pairs trading model. To determine whether a given strategy has deviated from its business rules, the company currently uses a relational database to store its positions and analyze this data as market prices change during the trading day. Although timeliness of the analysis has a huge impact on profits, the company can only obtain response times of about fifteen minutes using the relational database. Since investment markets can experience significant fluctuations within fifteen minutes, traders often need to eyeball market fluctuations and make trading decisions. The fund needs the ability to analyze its equity positions at market-speed, instantly alerting traders when a strategy goes out of range and enabling timely trades.