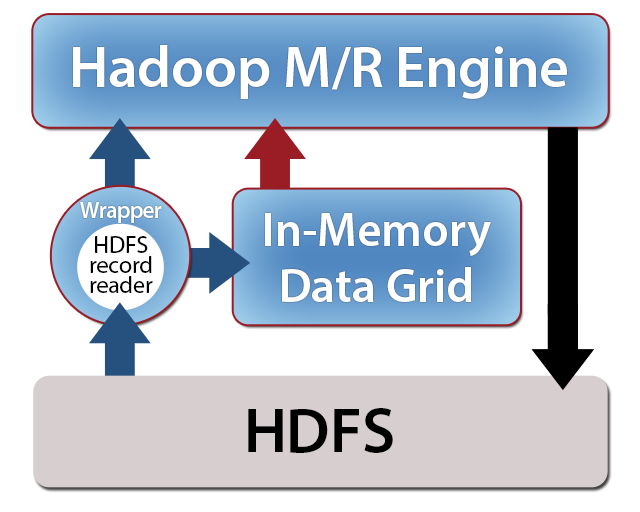
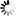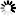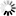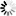ScaleOut hServer enables key/value pairs read from HDFS or another source to be cached within its IMDG to reduce data access time on subsequent MapReduce runs with the same data set. This is accomplished by wrapping the original input format with ScaleOut hServer’s dataset input format to create a Dataset Record Reader. If the specified data set is not already stored within the IMDG or if it has been modified, the Dataset Record Reader intercepts key/value pairs as they flow into the mapper and caches them within the IMDG. On subsequent runs in which the data set is available within the IMDG, the Dataset Record Reader retrieves key/value pairs from the IMDG, bypassing the underlying record reader, and serves them to the mapper. The above diagram conceptually shows how the Dataset Record Reader is used to wrap the underlying record reader and integrate with ScaleOut hServer’s IMDG.
To enable the Dataset Record Reader, the original input format should be replaced with the Dataset Input Format of type DatasetInputFormat. The original input format is then passed to the Dataset Input Format as a configuration property.
The following example illustrates the necessary changes in the program code to configure the Dataset Input Format:
Original Code.
job.setInputFormatClass(TextInputFormat.class);
Modified Code.
job.setInputFormatClass(DatasetInputFormat.class); DatasetInputFormat.setUnderlyingInputFormat(job, TextInputFormat.class);
Note that in current version of ScaleOut hServer, only file-based input formats which subclass FileInputFormat are supported as underlying input formats.