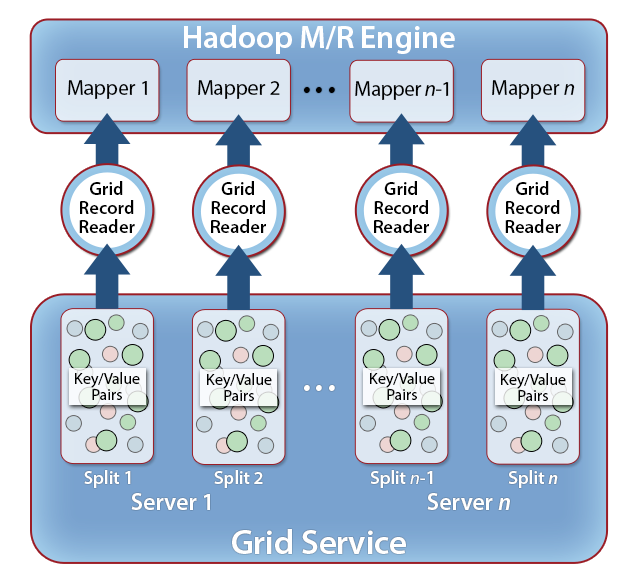
After you install ScaleOut hServer on the servers of your cluster, it will automatically discover and self-aggregate into an in-memory data grid (IMDG) spanning the cluster. Using ScaleOut StateServer’s Java APIs, your application can create, read, update, and delete key/value pairs in the IMDG to manage fast-changing, "live" data, keeping the data in the grid up to date as changes occur. At the same time, your Hadoop MapReduce program can read a collection of key/value pairs from the IMDG using the input formats provided by ScaleOut hServer. These input formats, which subclass GridInputFormat, retrieve key/value pairs from the IMDG and feed them to Hadoop’s mappers with minimum latency. Likewise, the output of Hadoop’s reducers optionally can be stored back into ScaleOut hServer’s IMDG using the GridOutputFormat and its associated Grid Record Writer, making these results available for subsequent Hadoop processing without data leaving the IMDG. You also can output results to HDFS or another persistent store.
The diagram below illustrates the use of the Grid Record Reader and Grid Record Writer. The Grid Record Reader is designed to input key/value pairs to Hadoop’s mappers with minimum latency. The GridInputFormat automatically creates splits of the specified input key/value collection to avoid network overhead when retrieving key/value pairs on all worker nodes:
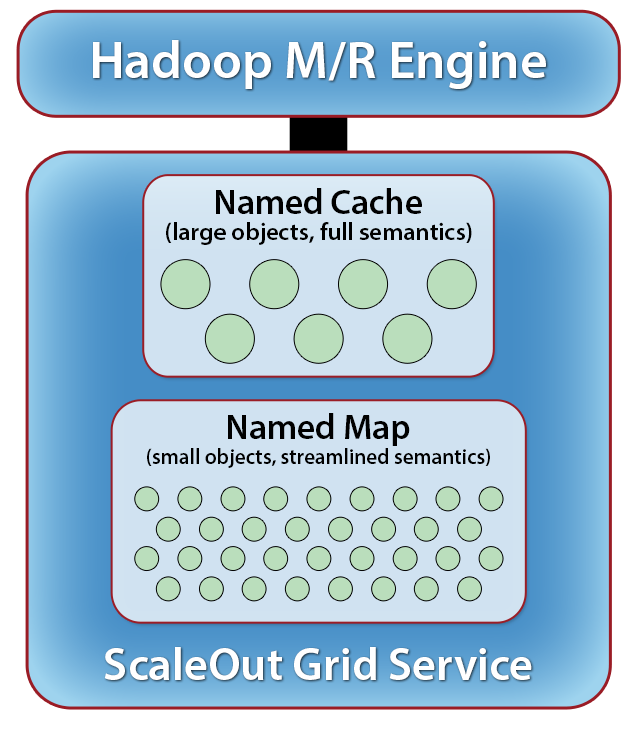
There are two ways to store objects in the IMDG, either through a NamedMap or through a NamedCache:
- NamedCache is optimized for bigger objects (e.g., 10KB or larger) and has advanced features, such as property-based query, dependencies, and pessimistic locking. The keys are restricted to strings, UUIDs, and byte arrays. To construct the named cache, use CacheFactory.
- NamedMap is a distributed Java ConcurrentMap optimized for storing small objects efficiently. A named map supports arbitrary keys and is coherent across all clients connected to the same IMDG. To construct the named map, use NamedMapFactory.
Using a NamedMap is the preferred way to store most MapReduce input and output data sets because it provides efficient storage of large numbers of relatively small keys and values. The key features of a NamedMap are:
- Bulk operations. To efficiently put or remove a large number of keys, use a BulkLoader view of the map which can be obtained by calling the getBulkLoader(…) method. This combines multiple map operations into chunks which provide higher overall bandwidth. putAll(…) also will provide the same performance gain if the keys and values are pre-computed and put into an intermediate map.
- Client cache with coherency policy. A customizable number of the recently read values can be stored in memory in the client cache. On subsequent reads, cached values for a key are returned if they are not older than the coherency interval. A coherency interval of 0 means that cached values are never used, and every read requires a call to the data grid. The client cache’s size can be configured by setClientCacheSize(…), and the coherency interval is configured by setCoherencyIntervalMilliseconds(…). By default, the client cache is turned off (coherency interval is 0).
- Parallel method invocation. Parallel method invocations can run simultaneously on all the hosts in the data grid, with each host performing operations on its local subset of keys. This helps to avoid moving data across the network and provides the best performance. Parallel invocations are defined by subclassing NamedMapInvokable. They require that an invocation grid is assigned to the named map by setInvocationGrid(…) [3]
- Parallel query. Parallel query returns a list of matching keys. To query a map, use executeParallelQuery(…), with a QueryCondition implementation as a parameter. Section 3.6 contains more information on queries and parallel method invocations.
- Custom serialization. Custom serialization can be used to efficiently store keys and values in memory. Custom serializers, which implement CustomSerializer, should be provided to the map factory method NamedMapFactory.getMap(…). Each instance of the client application across the grid should have the same custom serializers assigned to the map.
- Replication. A NamedMap can be configured to create replicas of its contents on multiple hosts. Enabling replication provides fault tolerance, i.e., it ensures that no data is lost in case of host failure at the expense of increased memory and network utilization. The number of replicas is determined by the max_replicas parameter in the soss_params.txt parameters file. By default, replication is disabled.
Please refer to the ScaleOut StateServer Java API documentation for more details.