In-memory computing enables real-time analytics to be integrated into operational systems so that fast-changing, “live” data can be instantly evaluated to provide feedback in milliseconds or seconds. As we have discussed in previous blogs, the key to scalable performance and fast response time lies in the use of data-parallel programming techniques. How can we structure these computations to ease their integration into operational systems?
The First Step: Object-Oriented Business Logic State
The evolution of in-memory data grids (IMDGs) over the past twelve or so years has paved the way for in-memory computing and analytics. IMDGs, such as ScaleOut StateServer, originally were developed to provide scalable, memory-based data storage for operational systems. For example, IMDGs host session-state and shopping carts for e-commerce web server farms and stock trades for financial systems. These applications and their associated IMDGs often run on clusters of physical or virtual servers to maintain fast response times for growing workloads.
Because web server applications, financial applications, and many others typically use object-oriented languages, such as Java, C#, or C++, to implement their business logic, they naturally structure fast-changing state information as collections of objects. For example, consider a website hosting an e-commerce application. This site’s shopping carts can be stored as instances of a “shopping cart” type, enabling business logic to directly manage these objects and leverage the benefits of object-oriented programming (e.g., data encapsulation and inheritance).
It is useful to think of a collection of objects as analogous to rows in a relational database table, with object properties corresponding to the table’s attributes. However, when objects are input from (or output to) a database or other persistent storage repository, a conversion to/from an object-oriented representation is performed. Tools such as Hibernate help perform these conversions.
To maximize ease of use, IMDGs are designed to integrate into an application’s object-oriented business logic and store fast-changing application state. They enable the application to seamlessly share data across servers and synchronize access by threads running on different servers. For example, consider a server cluster hosting a web server farm with a load-balancer distributing incoming browser connections to the web servers. If an e-commerce web application stores shopping carts within an IMDG, it can access the carts from any web server. Also, multiple browser connections can coordinate access to the shopping carts by using the IMDG’s APIs for distributed locking.
Note that IMDGs usually are not used for long term, persistent storage; that is the job of database and file servers. That said, IMDGs usually incorporate mechanisms to ensure the high availability of data after server outages so that they can be employed in mission-critical applications.
Partitioning Business Logic State into Object Collections
To enable IMDGs to store business logic state for scaled-out applications, their APIs provide an object-oriented view of data. IMDGs organize stored data as unstructured collections of objects, called “namespaces,” with each collection holding objects of a single type. These collections directly reflect mechanisms provided by object-oriented languages, such as Java maps and C# collections. To make objects globally accessible by the IMDG across a cluster of servers, the application supplies an identifying name, or “key,” for each stored object, usually in the form of a string, a number, or sometimes another object. For this reason, IMDGs are sometimes called “key-value stores.”
IMDGs automatically distribute objects within each namespace across the IMDG’s cluster of servers to maximize storage capacity and access throughput (by avoiding hot spots on individual servers). Well-designed IMDGs are “elastic” in the sense that they can transparently rebalance the storage workload as servers are added to handle more data or as servers are removed if the workload shrinks. In addition, IMDGs typically maintain redundant copies of stored objects on different servers so that data is not lost if a server fails or becomes unreachable. If such a failure occurs, the IMDG self-heals by restoring full redundancy to stored data on the surviving servers.
Take a look at the following diagram which depicts how an IMDG distributes collections of objects across a cluster of servers:
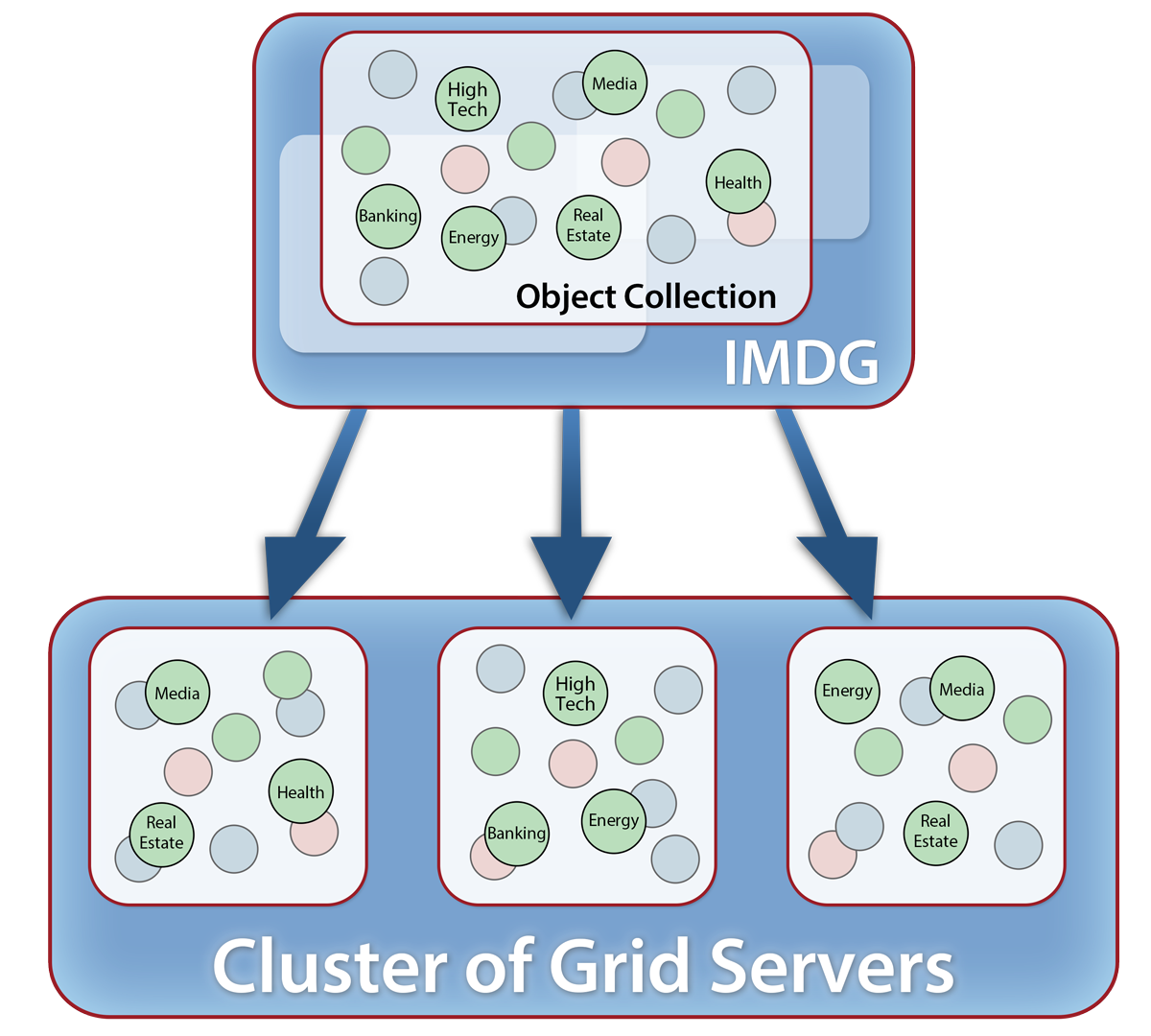
Because an IMDG’s memory is held in service processes running separately from applications, stored objects must be serialized into byte streams which are sent to the IMDG using inter-process or network communication. IMDGs typically store objects as “blobs” of serialized, uninterpreted data accessed by their keys. However, they also use client-side caches within the address space of applications to hold deserialized copies and thereby speed up retrieval.
Using Parallel Query to Select Objects
Because an IMDG runs on a cluster of servers, it incorporates scalable computing power that grows with storage capacity. IMDGs use this computing power both to scale access throughput and to select data using parallel query. IMDGs can query objects within a namespace by their object properties. Queries take the form of an expression which filters objects based on the values of these properties and generates a collection of keys identifying those objects which match the query criteria.
IMDG queries are similar to database queries except that they operate on object properties instead of relational attributes. For example, if an IMDG holds a collection describing equities in the stock market, a query could select all stocks which are in the high tech sector and have price/earnings ratios greater than 15. The following diagram depicts a parallel query in an IMDG:
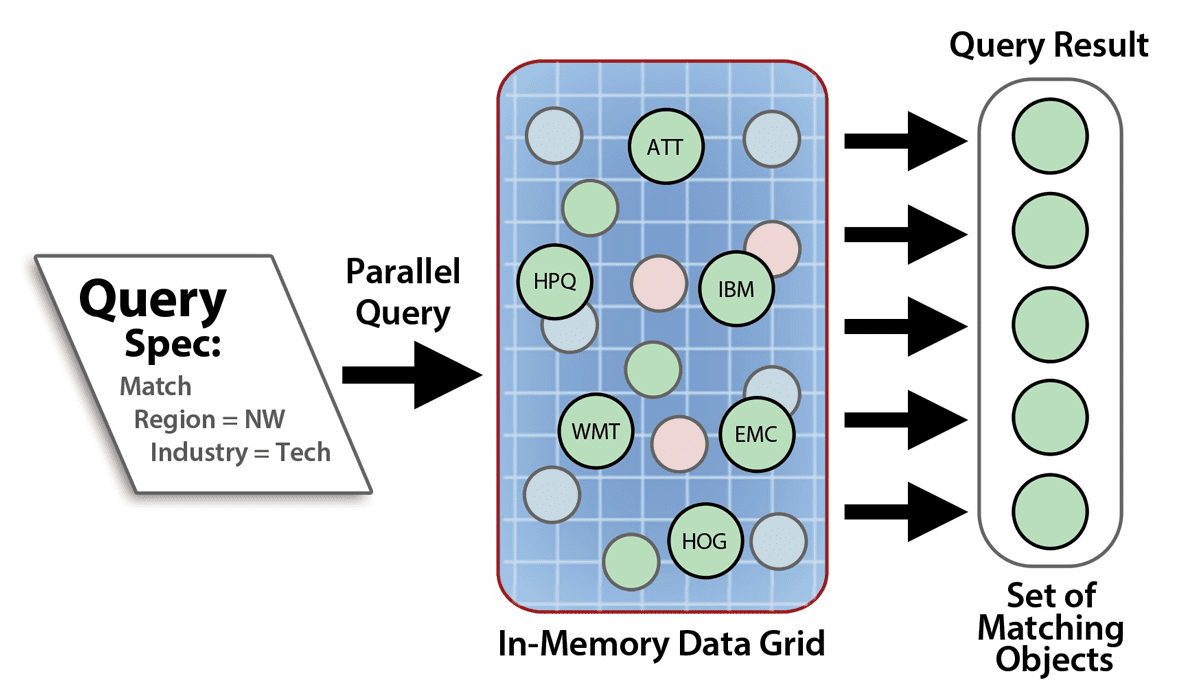
ScaleOut StateServer takes advantage of Microsoft’s language integrated query (LINQ) to implement C# queries with a straightforward syntax similar to SQL. It constructs Java queries by composing methods which filter property values and creating Boolean expressions of these filters.
Various techniques are available to index objects for fast query so that they do not have to be deserialized to evaluate their properties when a query is performed. The net effect is that IMDGs can take full advantage of the cluster’s computing power to quickly select the objects of interest within a large collection stored in the IMDG.
Parallel Queries Can Create Performance Bottlenecks
However, efficiently managing the results of a parallel query without creating a performance bottleneck is a major challenge. If a query matches many objects, a large set of keys must be collected and delivered to the requesting application, and this can consume a great deal of network bandwidth. For example, matching 1M objects with 40-byte keys requires delivering 40MB to an application, which can take half a second on a gigabit network. Moreover, the application has to retrieve all 1M objects to process the selected data, which can take several seconds depending on the amount and complexity of the data.
Another issue with parallel queries is that they must be used judiciously to avoid saturating the CPUs and network. Because each query generates work for all servers, if many application threads simultaneously perform queries, the total amount of work can grow quadratically and overload the servers or network.
The Solution: Data-Parallel Computing
While parallel queries provide a powerful means to identify the objects of interest for further analysis, the key to scalable speedup without performance bottlenecks is to analyze objects in place on the grid servers. Instead of shipping the keys and objects to an application thread for analysis, it is far more efficient to ship the analytics code to the IMDG’s servers for parallel analysis. This minimizes data motion, scales the computation, and ensures that results can be returned as quickly as possible.
When performing a data-parallel computation, a parallel query serves to filter the objects that are submitted for analysis on each grid server. This avoids the performance bottleneck caused by shipping keys and objects across the network. The data-parallel computation also reduces the usage of parallel queries by moving the analysis into the IMDG.
The object-oriented data model simplifies the construction of data-parallel analysis in several ways. First, it partitions the data set into a collection of logically related entities (instances of a type) which can be independently analyzed. These objects form the domain decomposition needed for parallel execution, as discussed in the previous blog. Second, it enables the analysis code to be conveniently represented as a method on the type. Lastly, it enables the results of the parallel analysis to be structured as another collection of objects, usually of a different type, which can be combined or fed to another data-parallel operation (as is the case with Hadoop MapReduce).
Because the IMDG distributes the objects within a collection to all grid servers, it automatically ensures that the domain for data-parallel execution is load-balanced across the cluster. This maximizes overall throughput by balancing the analysis workload across the servers.
For example, consider the financial services example we saw in the previous blog in which the IMDG holds a collection of “strategy” objects for a hedge fund, each of which represents a market sector, such as high tech or real estate, and holds the equity positions and rules for that market sector. A data-parallel computation can independently update each strategy object with a snapshot of market price changes and then evaluate the strategy to determine if stock trades are needed. By performing this analysis in parallel across all strategies, results can be generated in milliseconds instead of several minutes needed by conventional disk-based, sequential analysis.
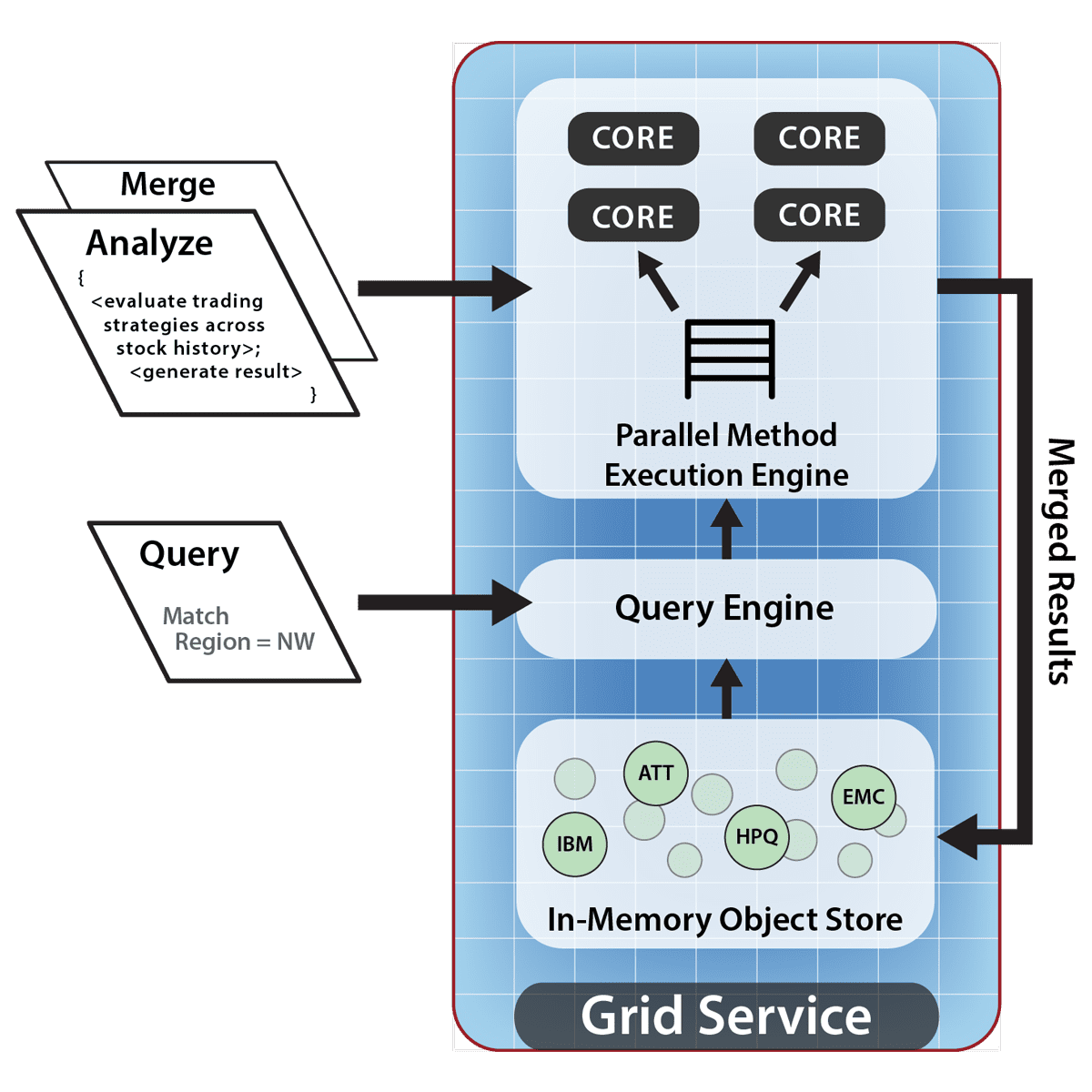
The following diagram shows how each IMDG server within a cluster can analyze local objects resulting from a parallel query, thereby avoiding data motion across the network. This diagram illustrates the multi-core “parallel method invocation” engine implemented by ScaleOut StateServer Pro. Note that locally selected objects are analyzed using the application’s Analyze method; analysis results then are combined by the Merge method and flow back into the server’s local memory for optional combining across servers.
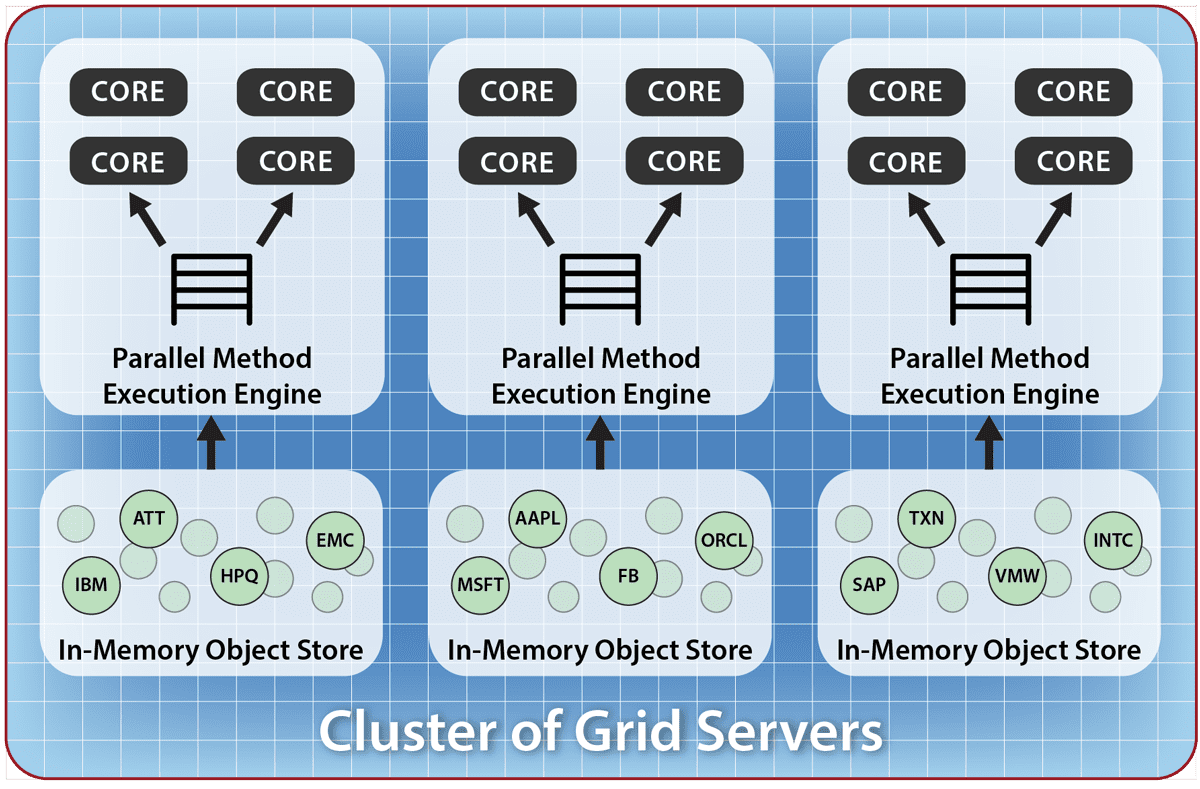
Each server in the IMDG’s cluster run a portion of the data-parallel computation on locally selected objects, as illustrated below:
To simplify running data-parallel analyses, some IMDGs, such as ScaleOut StateServer Pro, can ship the application code to all grid servers and initialize the execution environment (i.e., start up JVMs or .NET runtimes). In addition, the IMDG’s use of object collections streamlines multiple data-parallel operations. For example, ScaleOut hServer uses the IMDG to run both the Map and Reduce phases as data-parallel operations, staging intermediate data within the IMDG to minimize overall execution time. Object collections also reduce the complexity and overhead of Hadoop’s input and output formats and enable automatic optimizations (e.g., automatically creating splits and partitions).
Summing Up
Object-oriented programming gives IMDGs an efficient and well understood means to hold business logic state, perform queries, and structure data-parallel computations. This allows IMDGs to be seamlessly integrated into operational systems and perform real-time analytics on “live” data, opening up many new opportunities to add value to these systems.