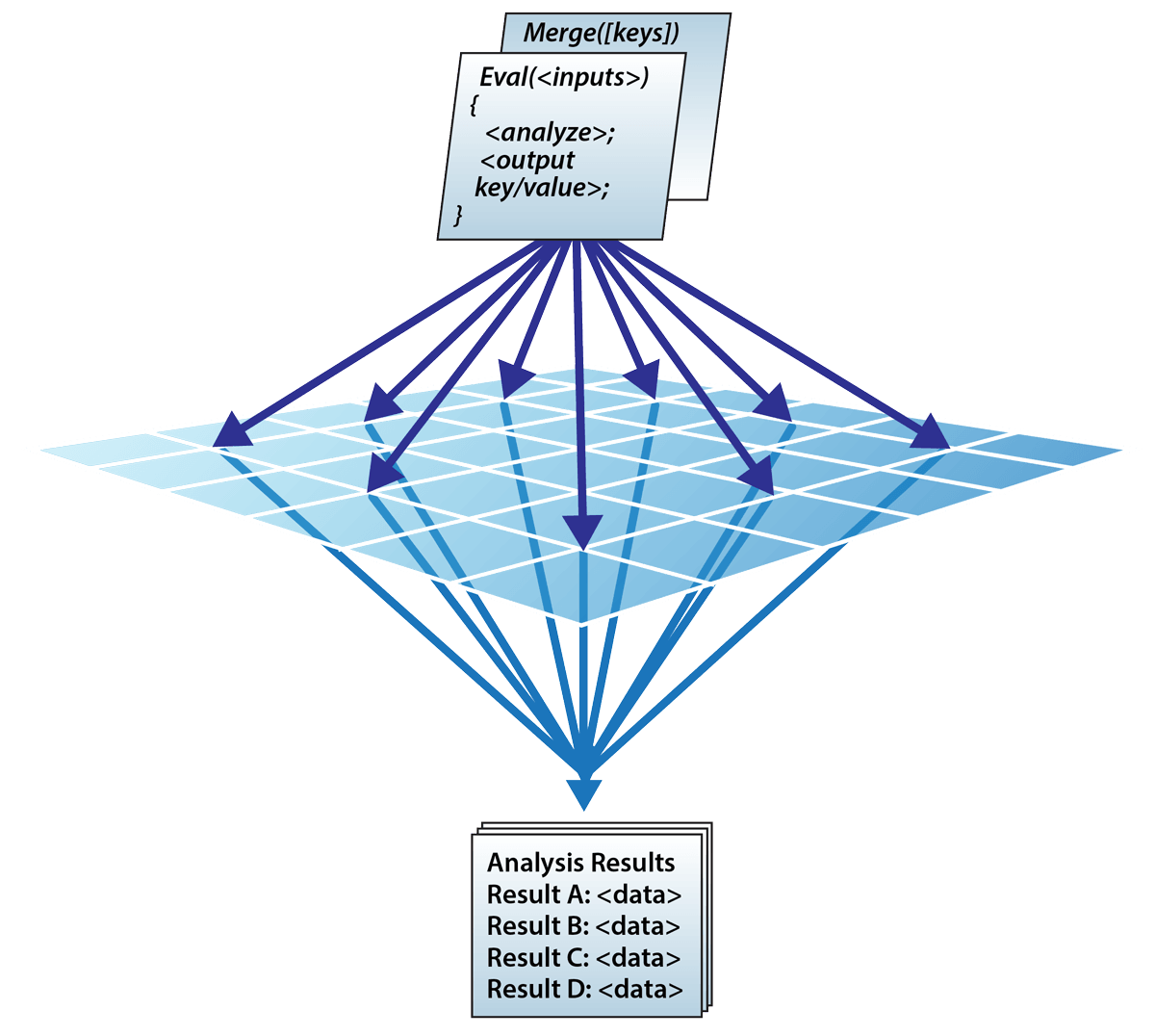
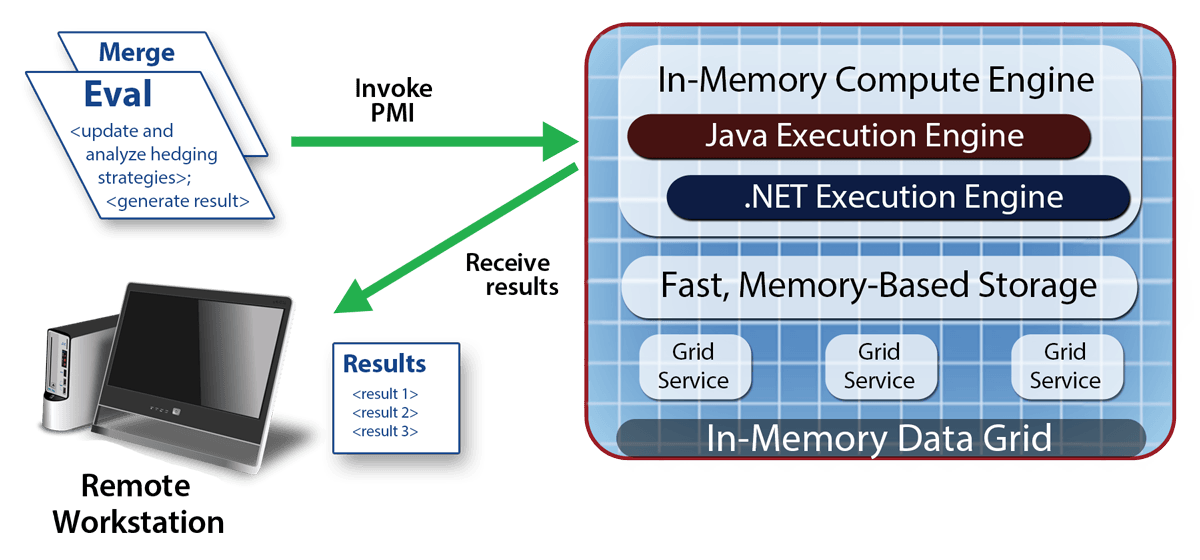
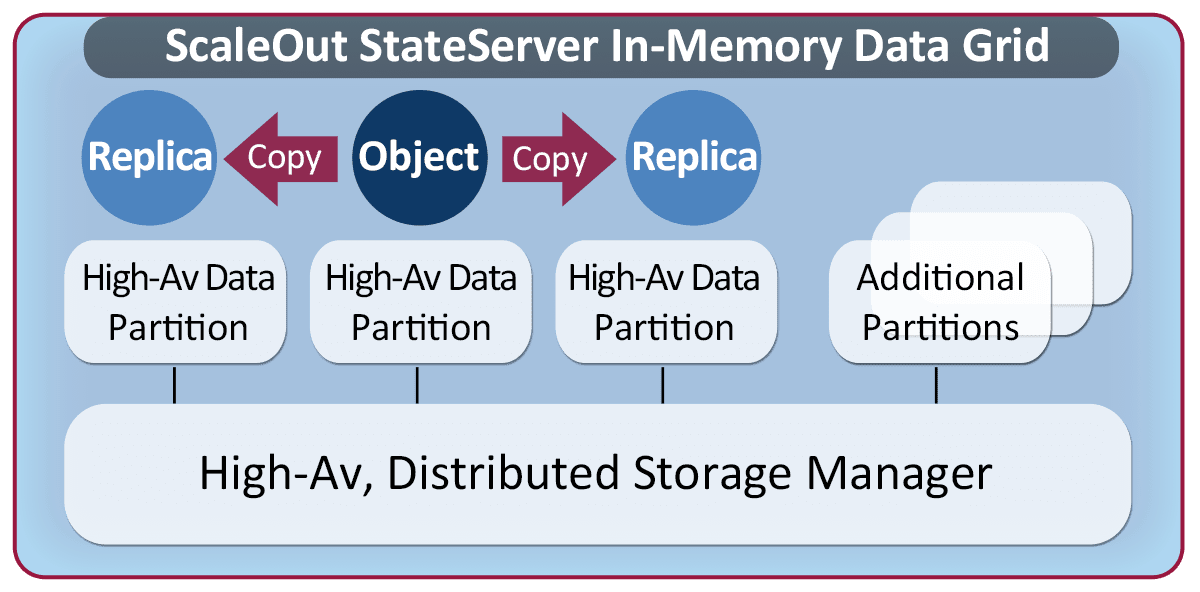
Fast Access to Data
Scalable Throughput Ensures Fast Access
In comparison to disk-based storage, in-memory data grids (IMDGs) dramatically lower access latency for fast-changing data. The key to maintaining this fast access as the workload grows is to scale throughput by adding servers. The IMDG distributes stored data across all servers within a cluster, enabling all servers to simultaneously share a portion of the access workload. This enables linear throughput scaling without bottlenecks (“hot spots”) and keeps access times from climbing.
To scale throughput, ScaleOut’s IMDG technology automatically partitions stored data across all grid servers. As servers are added to the grid, ScaleOut automatically repartitions and rebalances the workload to increase storage capacity and increase throughput. Likewise, if servers are removed or fail, ScaleOut coalesces stored objects on the surviving servers and rebalances the storage workload as necessary.
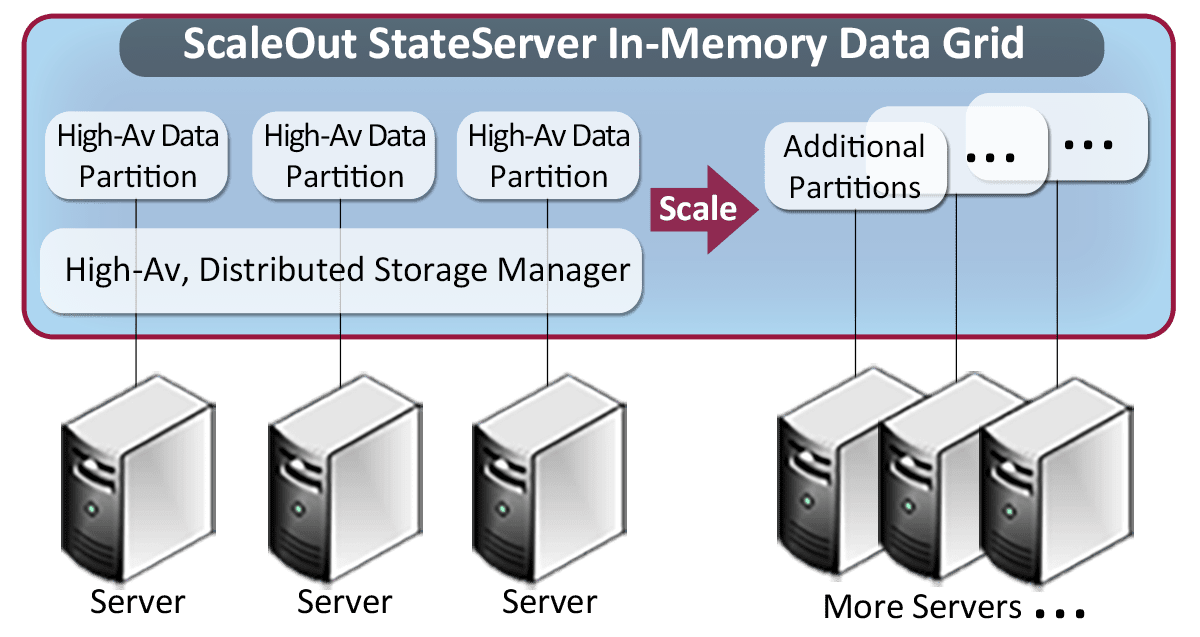
ScaleOut’s IMDG automatically partitions data across grid servers.
Client Caching Reduces Access Time
For reliability and manageability, IMDGs typically implement “out of process” in-memory data stores. As with database servers, accessed data must be serialized and communicated to and from an IMDG using network connections, and this imposes an overhead that impacts access times.
To minimize access delays, ScaleOut’s IMDG incorporates a cache within its client API libraries for recently accessed objects. By holding references to these objects for future access, it eliminates repeated network transfers and deserialization delays. This significantly shortens access times to near “in process” levels for objects which are repeatedly read without an intervening update. (For example, tests with 10 KB objects and 20:1 read/update ratio have demonstrated a 6X reduction in access latency.) Client caching also reduces resource usage by lowering both network and CPU overheads.
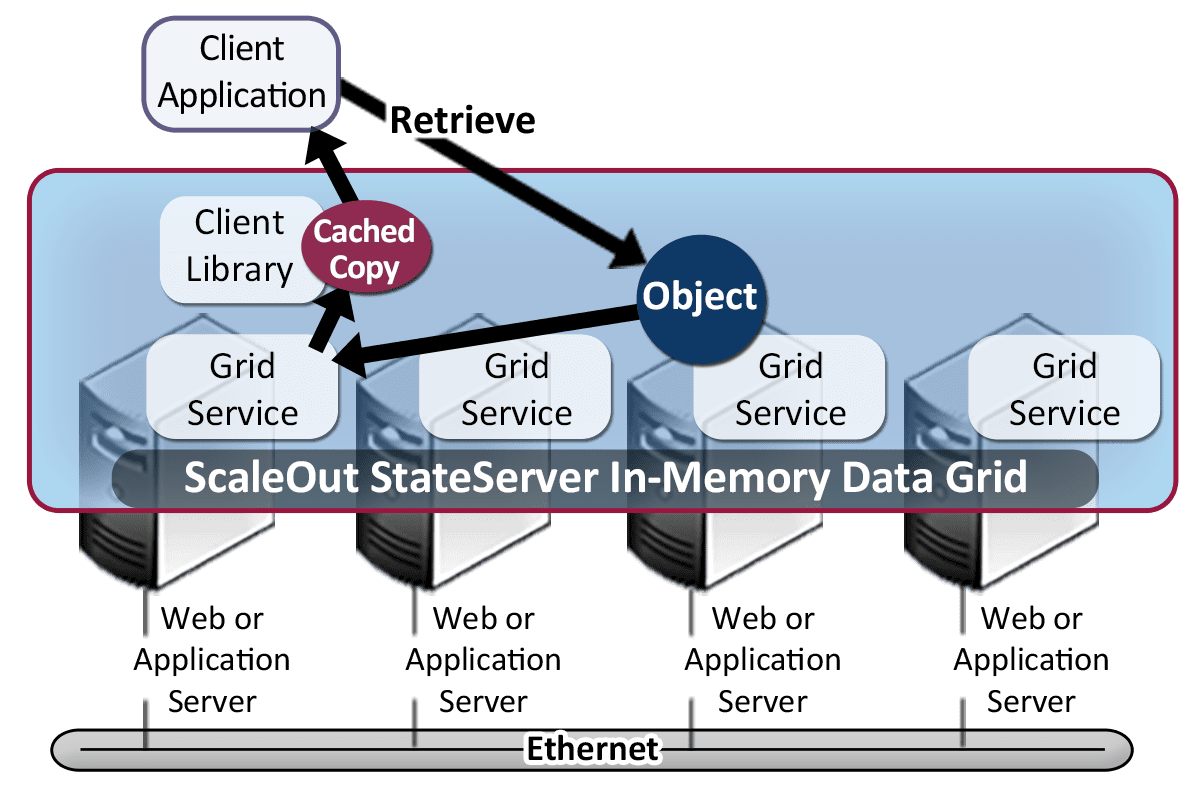
Client caching significantly lowers read access times.
Importantly, ScaleOut’s client caches automatically maintain coherency with the IMDG’s data store and implement “sequential consistency” semantics. This offers the simplest possible development model; it ensures that applications can safely store and access objects within multi-threaded applications and transparently benefit from the client cache’s performance gains without any changes to program structure.